SAP Predictive Analytics: итог долгого пути развития инструментов анализа данных SAP (часть 1)
Эта статья открывает цикл из трех публикаций, в которых будут рассмотрены базовые сведения о наборе инструментов SAP Predictive Analytics и история его появления. В этой статье описан компонент автоматизированного анализа SAP Predictive Analytics (в частности, классификационный анализ). Далее показано как сохранить деньги используя предлагаемые методы анализа данных.
Ключевое понятие
В первой статье цикла Нед Фолк рассматривает все инструменты интеллектуального/прогнозного анализа, предлагаемые SAP (обзорно), а затем подробнее останавливается на самых новых инструментах, SAP Predictive Analytics. Вы узнаете, как с помощью компонента Automated Analysis в системе SAP Predictive Analytics (ранее эта система поставлялась отдельно под именем SAP InfiniteInsight) можно провести классификацию клиентов и прогнозировать, кто из них будет покупать ваши продукты.
SAP занимается инструментами для интеллектуального анализа данных уже очень давно. Новейшие инструменты выполняют статистический анализ в пользовательских интерфейсах с пошаговыми инструкциями, которые можно быстро развернуть и освоить. Вершиной этого долгого пути развития является система SAP Predictive Analytics. В этой статье представлены базовые сведения, необходимые для эффективной работы с данным инструментом.
Определение интеллектуального анализа данных и его краткая история
Для многих термин интеллектуальный анализ данных (Data Mining) означает детализацию или выбор дополнительных строк данных. Например, многие считают, что примером интеллектуального анализа данных (при работе с выходными списками показателей продаж по месяцу и клиенту) является фильтрация по определенному месяцу и детализация по номерам компонентов для клиента в данном месяце. Однако это вовсе не так. Интеллектуальным анализом данных (согласно Merriam-Webster.com) является «процесс поиска в больших объемах автоматизированных данных с целью выявления практически применимых моделей или тенденций».
Со временем возможности анализа данных существенно расширились. Это занятие перестало быть прерогативой небольшой группы ученых в университетах, которые могли похвастаться наличием суперкомпьютеров. Теперь эксперты по различным бизнес-процессам могут выполнять анализ данных в базовых бизнес-сценариях с помощью простых и эффективных инструментов. В своей работе я в течение многих лет использовал инструменты анализа данных SAP. Первый набор инструментов SAP для анализа данных был разработан на базе SAP BW группой по SAP CRM, поскольку анализ данных имеет центральное значение для оптимизации бизнес-процессов CRM самыми разными способами. Например, с помощью:
- Кластеризации для объединения клиентов в группы для таргетированного маркетинга.
- Деревьев принятия решений для прогнозирования поведения покупателей.
- Ассоциативного анализа для предложения к покупке дополнительных сопутствующих продуктов при выборе основного продукта.
Первоначально набор инструментов для анализа данных состоял из Analysis Process Designer (APD) и Data Mining Workbench. Оба инструмента входили в базовую лицензию SAP BW и были тесно интегрированы с SAP CRM, что делало их весьма привлекательными для компаний.
Два других более новых набора инструментов для анализа данных поставляются с интеграцией в новую базу данных SAP HANA: алгоритмы анализа данных Predictive Analysis Libraries (PAL) и Application Function Modeler (AFM). AFM — графический инструмент моделирования для передачи данных в алгоритм и обратно. С помощью этих инструментов программисты и опытные специалисты по моделированию в SAP HANA могут повысить эффективность алгоритмов анализа данных. Кроме того, доступен новый инструмент, SAP HANA Analysis Process (HAP). Этот инструмент разработан на базе SAP BW и позволяет специалистам по моделированию в SAP BW получать доступ к HANA PAL через сервер приложений SAP BW.
Большинство этих инструментов связывает вместе решение SAP Predictive Analytics, о котором будет подробно рассказано ниже. Все эти инструменты объединяют готовые алгоритмы анализа данных, составленные на базе сложных математических расчетов, и позволяют извлекать и предварительно обрабатывать данные с использованием этих алгоритмов.
Каждый из этих инструментов имеет свои преимущества и недостатки. Обзорно эти сведения представлены в табл. 1. Данная матрица не является исчерпывающей, но содержит общие сведения по каждому из этих инструментов.
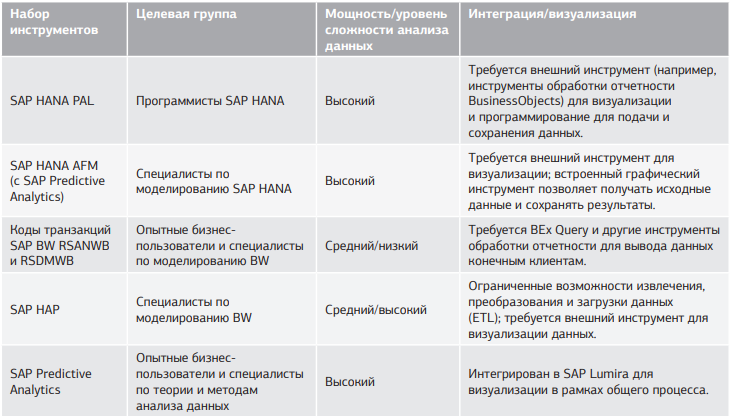
Табл. 1. Краткий обзор возможностей инструментов анализа данных SAP
SAP Predictive Analytics
После краткого экскурса в историю перейдем к более подробному описанию последнего инструмента в табл. 1, SAP Predictive Analytics. Название Predictive Analysis перешло к SAP с приобретением BusinessObjects, но с тех пор этот инструмент сильно изменился. С одной стороны, этому способствовало появление SAP HANA и SAP Lumira (инструмент для визуализации данных), а с другой — приобретение компании по анализу данных KXEN. Преимуществами инструмента KXEN InfiniteInsight являлись его мощные алгоритмы анализа данных и удобство работы даже для самых неопытных пользователей. Это делало продукт KXEN привлекательным для разных пользователей, от бизнес-аналитиков до начинающих специалистов по обработке данных. После приобретения KXEN этот простой в использовании продукт (не на базе BW) получил название SAP InfiniteInsight.
Компания SAP поняла, что инструментов стало слишком много. В соответствии с новой концепцией упрощения SAP требовалось повысить удобство использования и снизить сложность инструментов анализа данных при сохранении высокого качества результатов для всех классов пользователей. Так мы получили новый набор инструментов SAP Predictive Analytics 2.0. Установив только одну систему, вы получаете все преимущества Predictive Analytics и бывшего когда-то отдельным инструментом SAP InfiniteInsight. Я уверен, что в будущем эти инструменты будут интегрированы друг с другом еще более тесно, но и уже сейчас мы видим значительно упрощенный ландшафт.
На данный момент в новом решении SAP Predictive Analytics 2.0 центральный компонент предыдущей версии Predictive Analysis относится к Expert Analytics, а функции бывшего SAP InfiniteInsight размещаются в Automated Analytics, см. Рис. 1.
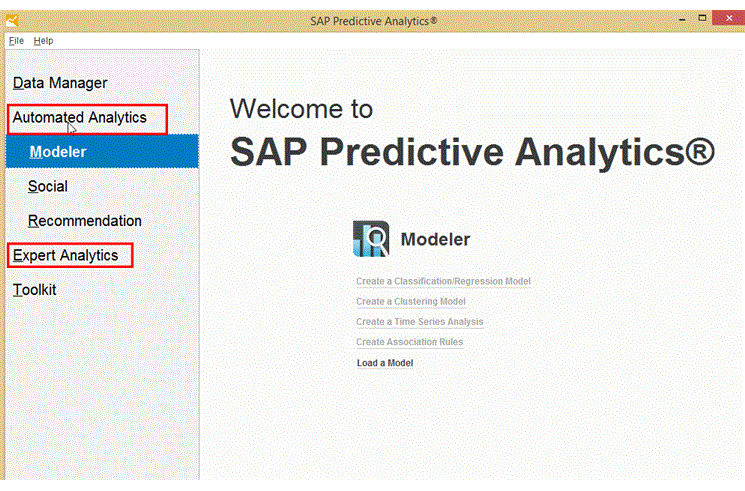
Рис. 1. Главная страница SAP Predictive Analytics 2.0
Основы прогнозной аналитики: Automated Analytics — модель классификации
Основной функцией инструмента Automated Analytics является сопровождение пользователя в работе с моделью анализа данных от начала и до конца. (Вводное описание функции Expert Analytics будет представлено в другой статье данного цикла.)
Чтобы наглядно представить функциональность ассистента автоматического анализа, рассмотрим процесс создания новой модели классификации. Однако это лишь один из вариантов. Анализ можно выполнять, помимо прочих, регрессионным или ассоциативным методом.
Примечание.
Полнота раскрытия информации: технические особенности моей лицензии SAP Predictive Analytics не позволяют мне показать здесь обновленные снимки экранов инструмента Automated Analytics как компонента Predictive Analytics. Используемые в статье снимки экрана выполнены в предыдущей версии, SAP InfiniteInsight. Однако по сути данной статьи это не помешает восприятию и не искажает детали процесса.
Если вы работаете в старой системе SAP InfiniteInsight, запустите ассистент для демонстрации метода классификации, выбрав опцию Create a Classification/Regression Model (Создать модель классификации/регрессии), см. Рис. 2. Если у вас более новая версия 2.0, выберите опцию Modeler (Средство моделирования) в Automated Analytics, а затем опцию Classification/Regression (Классификация/регрессия).
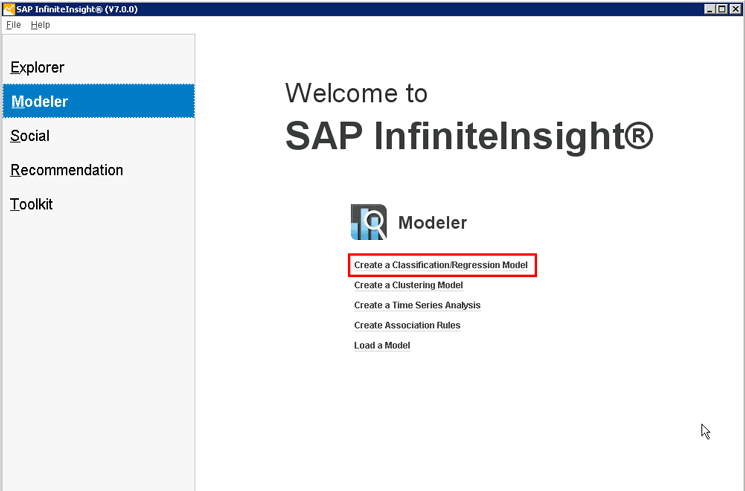
Рис. 2. Выбор опции создания новой модели классификации/регрессии
Далее вы с помощью ассистента быстро пройдете логичную последовательность необходимых шагов для создания новой модели классификации (или регрессии), как подробно описано ниже.
Модель классификации: шаг 1, получение данных из источника для обучения модели
Задачей модели классификации является определение статистических отношений между атрибутами и спрогнозированными результатами на основе набора данных, в котором существует множество переменных (поля атрибутов с данными) вместе с информацией о результате прогнозных переменных. Например, данные для многих сварных швов могут включать в себя имя сварщика, его опыт работы, дату производства, тип и производителя сварочного аппарата (атрибуты). Кроме того, чтобы эффективно применить все эти данные для обучения модели классификации, необходимо знать ответ на следующий вопрос: Разошелся ли какой-либо сварной шов в этой работе (прогнозная переменная)?
Далее после применения модели к обучающему набору данных с известными результатами модель следует применить к другому набору данных для прогнозирования результатов, которые вам неизвестны. В случае со сваркой вы собираете информацию о сварных швах, которые не разошлись, и прогнозируете их дальнейшее поведение.
В моем примере используются не сварные швы, а клиенты. С помощью атрибутов клиентов создается модель классификации, которая позволит определять покупательское поведение клиентов как прогнозную переменную. А именно, с помощью инструмента Automated Analytics я попробую на основе атрибутов клиентов спрогнозировать, купят ли они продукты, рекламируемые компанией X.
После выбора классификации/регрессии (рис. 3) ассистент предлагает местоположение источника данных для начального обучения модели. В данном случае источником является простой файл с разделенными запятой значениями (CSV) на моем ПК. Вы можете использовать данные из любого количества источников (например, из любых таблиц и ракурсов базы данных SAP HANA).
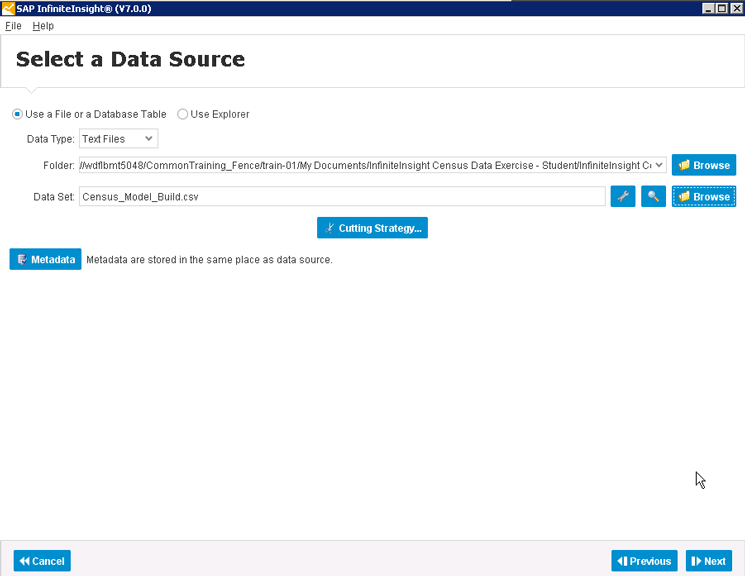
Рис. 3. Выбор источника данных для обучения модели
После выбора источника данных нажмите кнопку Next (Далее), которая показана в нижнем правом углу рисунка. Появится экран Data Description (Описание данных). Сначала этот экран открывается без метаданных в нижней части, но после нажатия кнопки Analyze (Анализ) справа выполняется синтаксический анализ данных (в данном случае файла CSV) с предложением типов полей и некоторых других метаданных, релевантных для модели данных. После синтаксического анализа эти метаданные отображаются в нижней части экрана, показанного на рис. 4.
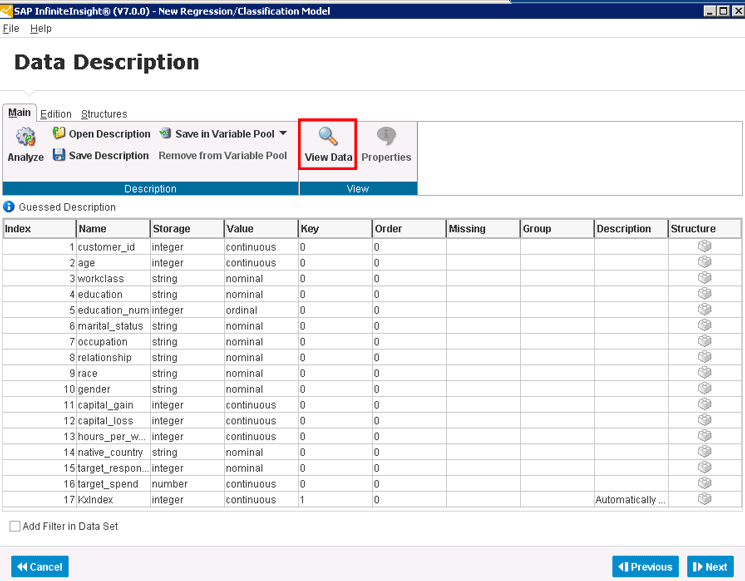
Рис. 4. Описание метаданных для данных обучения после анализа
Этой математической модели требуется информация о том, какие поля имеют числовые значения, а какие содержат прочие символы. Более того, модель должна знать, являются числа непрерывными (доход клиента), ординальными (длительность обучения клиента) или номинальными (незначащий числовой код, присвоенный для обозначения цвета).
Ассистент выполняет большой объем работы по определению таких метаданных, но если у вас есть сведения, которыми не обладает система, вы должны изменить настройки и помочь модели составить более точный прогноз. Например, если вам известно, что поле Color (Цвет) может иметь только три варианта значений (1= красный, 2 = синий и 3 = зеленый), а ассистент некорректно определил значение в этом поле как непрерывное, вам необходимо будет исправить ассистент и определить значение в поле как ординальное, а не непрерывное.
После синтаксического анализа данных нажмите кнопку View Data (Просмотреть данные), выделенную красной рамкой на рис. 4. Появятся данные, которые будут использованы в модели на первом этапе обучения (рис. 5). Как видно на рис. 5, здесь представлены демографические данные по клиентам. Справа на экране (на рисунке не показано) отображается поле target_response. В этом поле указано значение 0, если клиент, с которым вы общались, не купил продукт, и 1, если купил.
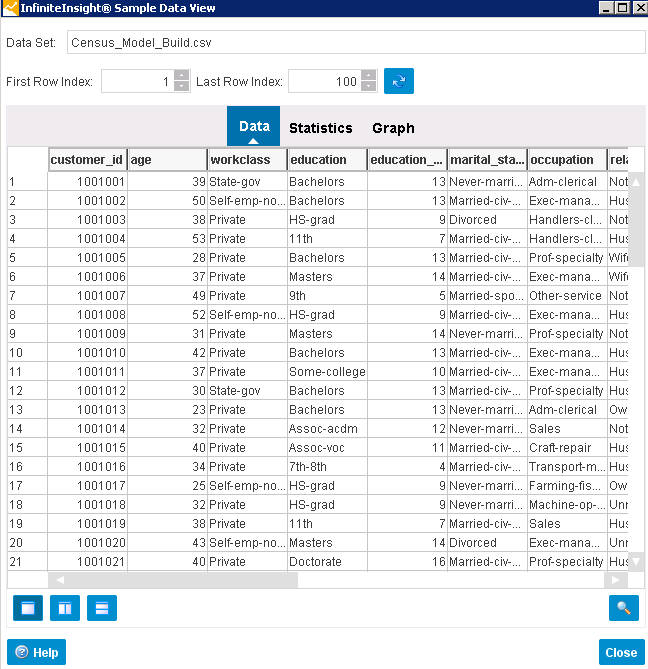
Рис. 5. Просмотр данных обучения модели
После синтаксического анализа данных и присвоения правильного значения (например, ординал, номинал и т. д.) нажмите кнопку Close (Закрыть). Снова появится экран, показанный на рис. 4. Здесь можно продолжить работу с набором данных, как описано ниже.
Модель классификации: шаг 2, выбор переменных
Нажмите кнопку Next (Далее) в правом нижнем углу (рис. 4). Откроется экран, на котором можно выбрать переменные для модели (рис. 6). Здесь специалист по моделированию (в данном случае вы) может выбрать переменные, которые должны учитываться в модели. В этом контексте переменные — это просто поля, описывающие клиентов и их покупательское поведение. Они называются переменными, поскольку являются гибкими факторами, которые модель может, но не обязана учитывать.
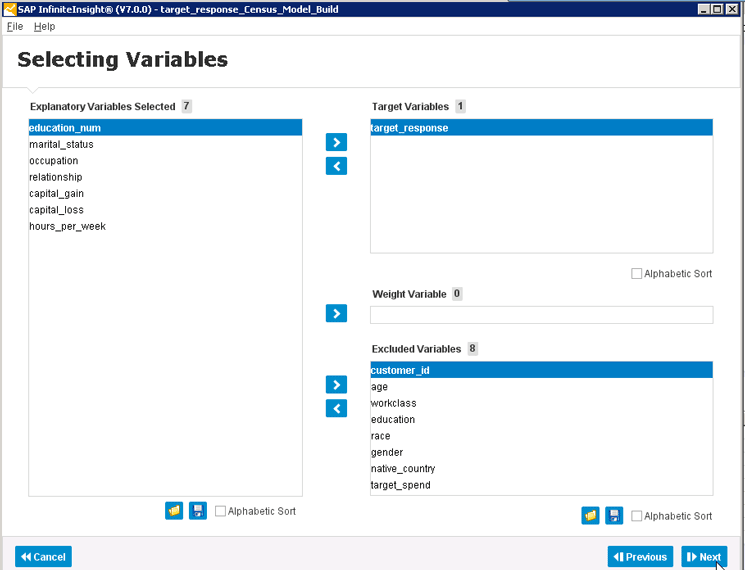
Рис. 6. Выбор переменных для модели
На этом экране необходимо выбрать по крайней мере одну переменную, которая будет целевой. Кроме того, в этом случае я решил исключить некоторые поля (с данными переписи) из модели анализа. Исключены переменные (нижний правый угол на рис. 6) раса, пол и некоторые другие. Я сделал это в целях демонстрации, но у вас вполне могут быть причины исключить некоторые переменные по техническим или юридическим причинам, либо в соответствии с особенностями бизнеса.
В первом случае с технической точки зрения функция инструмента позволяет показать переменные, максимально влияющие на результат модели. Поскольку каждая переменная повышает сложность модели и увеличивает время выполнения, исключение малозначимых для прогноза переменных может быть весьма целесообразно. С точки зрения бизнеса вычислять значения по некоторым переменным на следующем этапе прогнозирования, когда применяется модель, может оказаться слишком затратно. Например, вам потребуется заплатить много денег за информацию о возрасте каждого клиента, а модель показывает, что возраст не слишком сильно влияет на точность ее прогнозов. Если вы располагаете подобной информацией, исключите такие переменные.
Оформите подписку sappro и получите полный доступ к материалам SAPPRO
Оформить подпискуУ вас уже есть подписка?
Войти