Предсказательная аналитика от SAP
Обзор продукта SAP Predictive Analytics для прогнозной аналитики и методологии CRISP-DM для анализа данных
Оглавление
Predictive Analytics – новый инструмент от SAP
Этап 1: Понимание бизнеса (Business Understanding Phase)
Этап 2: Понимание данных (Data Understanding)
Этап 3: Подготовка данных (Data Preparation)
Этап 4: Моделирование (Modeling)
Этап 6: Развертывание (Deployment)
Этап 7: Мониторинг (Monitoring)
Автоматизированное моделирование
Вместо введения
В марте 2017 года на open.sap.com завершился замечательный курс «Getting Started with Data Science», посвящённый предсказательной (предиктивной) аналитике от SAP. Курс предназначен для ознакомления с методологией анализа данных, возможностями нового продукта, и даёт вводные знания по машинному обучению. Также можно скачать и установить 60-дневную ознакомительную версию пакета SAP Business Objects Predictive Analytics 3.1 и тестовые наборы данных. Курс содержит несколько практических примеров, которые могут быть выполнены самостоятельно на основе предоставляемых наборов данных. Это позволит составить собственное представление о продукте, рекламу которого вы видите на Рис.1.

Рис.1 Реклама продукта SAP Predictive Analytics
Так что же такое предсказательная аналитика? Вот, что по этому поводу пишет Wikipedia:
Предсказательная аналитика (прогнозная аналитика, предиктивная аналитика от англ. predictive analytics) — класс методов анализа данных, концентрирующийся на прогнозировании будущего поведения объектов и субъектов с целью принятия оптимальных решений.
Предсказательная аналитика использует статистические методы, методы интеллектуального анализа данных, теории игр, анализирует текущие и исторические факты для составления предсказаний о будущих событиях. В бизнесе прогнозные модели используют паттерны, найденные в исторических и выполняемых данных, чтобы идентифицировать риски и возможности. Модели фиксируют связи среди многих факторов, чтобы сделать возможной оценку рисков или потенциала, связанного с конкретным набором условий, руководя принятием решений о возможных сделках.
Предсказательная аналитика развивается вместе с Наукой о данных - разделом информатики, изучающий проблемы анализа, обработки и представления данных в цифровой форме. Объединяет методы по обработке данных в условиях больших объёмов и высокого уровня параллелизма, статистические методы, методы интеллектуального анализа данных и приложения искусственного интеллекта для работы с данными, а также методы проектирования и разработки баз данных. Благодаря науке о данных появилась новая кросс-индустриальная специальность «исследователь данных» (data scientist), которая считается привлекательной, высокооплачиваемой и перспективной профессией.
Для прогнозирования используются различные методы машинного обучения, анализа данных, деревья решений, регрессионный анализ, нейронные сети и глубокое обучение. Это та область, где объединяется анализ бизнес-процессов, анализ клиентов с математикой, статистикой, эконометрикой.
В исследовании «Gartner’s Top 10 Strategic Technology Trends for 2017» расширенное машинное обучение выделено как тренд под номером 1. Прогнозируется активное развитие систем искусственного интеллекта (AI) и машинного обучения (ML), которые включают в себя такие технологии, как глубокое обучение, нейронных сетей и обработки естественного языка. Будут развиваться продвинутые системы, которые будут самостоятельно обучаться, извлекать знания, предсказывать, адаптироваться и, потенциально, работать автономно. Системы могут предсказать будущее и изменить собственное поведение, что приводит к созданию более интеллектуальных устройств и программ. Сочетание доступных параллельных вычислительных мощностей, усовершенствованных алгоритмов и больших наборов данных стартует новую эру в предиктивной аналитике.
Новые интеллектуальные приложения и Интернет вещей также широко используют технологии машинного обучения.
В банковском деле, методы искусственного интеллекта и машинного обучения используются для мониторинга текущих операций в режиме реального времени с целью выявления мошенничества. У банков есть доступ к сотням тысяч кредитных историй. Каждый клиент имеет свои характеристики: социально-демографические, историю трат, историю покупок продуктов, историю использования кредитного лимита. Классическая скоринговая задача состоит в том, чтобы дать прогноз вероятности проблем, которые возникнут с вновь выдаваемым кредитом, на который оформил заявку клиент.
Машинное обучение – это не панацея. Многие вещи делаются гораздо более простыми способами. Например, в маркетинге, RFM-сегментацией клиентов по давности последней покупки, частоте и величине покупок. Но использование методов предиктивной аналитики позволяет упросить работу эксперта. Направить его усилия на поиск новых возможностей, новых типов сегментации, новых способов предложить клиенту именно то, что подойдёт ему.
Predictive Analytics – новый инструмент от SAP
Методы прогнозной аналитики в том или ином виде присутствуют во многих продуктах SAP. Управление складскими запасами или создание оптимальных логистических цепочек используют различные методы оптимизации. Но впервые эти методы вынесены в отдельный десктопный продукт SAP Predictive Analytics.
Благодаря платформе SAP HANA компания SAP объединила аналитический функционал, обеспечила интеграцию инструментов анализа с данными, получаемыми из различных источников (Рис. 2).
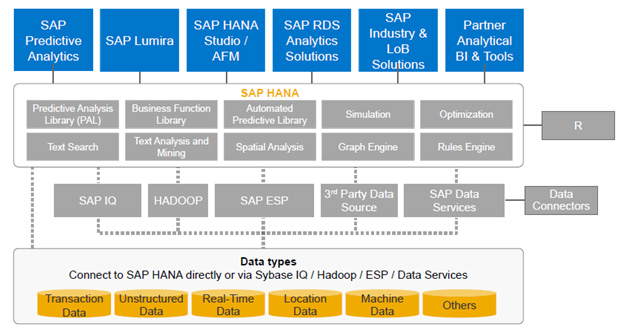
Рис. 2 Архитектура аналитических решений на базе платформы SAP HANA
В ядро SAP HANA встроен Predictive Analysis Library (PAL), который предназначена для построения высокопроизводительных предиктивных приложений. PAL является библиотекой для выполнения in-memory процессов анализа данных и статистических расчётов (Рис. 3). PAL призвана обеспечить высокую производительность на больших наборах данных в задачах аналитики в реальном времени.
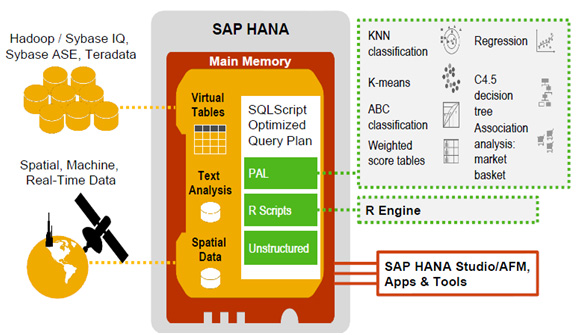
Рис.3 Структура библиотеки Predictive Analysis Library для прогнозной аналитики
Интеграция с R
При изучении аналитических возможностей платформы SAP HANA мне понравилась глубокая интеграция SAP HANA и R (Рис. 4). Это даёт возможность подключать внешние библиотеки и использовать алгоритмы, разработанные специалистами по анализу данных в самых различных отраслях – от глубокого обучения до геномного анализа. В библиотеке CRAN сейчас доступно более 10000 пакетов для решения различных прикладных задач. Бывает, что вместе со статьёй в рецензируемом журнале, исследователи сразу выкладывают библиотеку, где реализованы описанные методы.
Важной поддержкой для использования R является проект компании Microsoft R Open. Встроенные механизмы управления версиями пакетов позволяют получать воспроизводимые результаты на различных платформах.
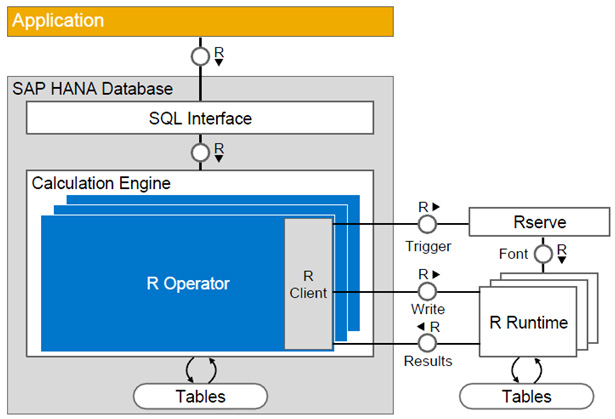
Рис. 4 Интеграция SAP HANA с программным окружением аналитического инструментария на R
Такая архитектура позволит SAP тратить ресурсы на улучшение визуальных и функциональных свойства продукта. А доступ к самым современным методам анализа данных пользователь сможет получить самостоятельно, подключив соответствующую библиотеку. Это позволяет строить гибкие решения под требования бизнес-заказчика и презентовать результаты в понятном виде.
Методология CRISP-DM
SAP начал использовать единый промышленный стандарт и отказался от того, чтобы в придумать собственное уникальное название для общепринятых вещей. Продукт и методология понятны специалистам с маркетинговым, эконометрическим или статистическим образованием. В своё время, при освоении SAP функционала меня поставило в тупик слово «деривация», которое использовалось как синоним слов «определение», «вычисление». Хотя в русском языке оно изначально имело несколько иной смысл. Использование общепринятой методологии и понятий позволяет избежать подобных смысловых коллизий.
Методология CRISP-DM (Cross Industry Standard Process for Data Mining), которая использована в продукте SAP, начала разрабатываться как проект Европейского союза в рамках программы стратегических инициатив ESPRIT. Проект возглавили несколько компаний: SPSS, Teradata, Daimler AG, NCR Corporation и OHRA, который на то время были лидерами в работе с анализом данных.
Другой лидер рынка, компания SAS использует собственную методологию SEMMA, которая реализована, отчасти, в среде SAS Data Mining Solution.
На данный момент CRISP-DM является самым известным стандартом работы с данными для задач извлечения знаний, предсказания, построения устойчивых моделей. Анализ данных является непрерывным процессом со многими циклами и обратными связями.
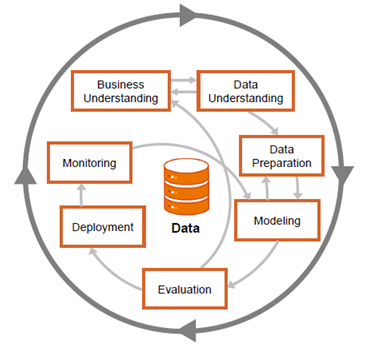
Рис. 5 Шаги методологии CRISP-DM с возможными направлениями перехода между этапами
SAP использует улучшенный вариант методологии CRISP-DM, включающей 7 этапов с понятными шагами и результатами после каждого шага (Рис. 5). При этом последовательность этапов не является строгой. В процессе работ с данными, моделями, при оценке результатов или при использовании модели на практике, возможен возврат на предыдущие этапы проекта, чтобы сделать уточнения, провести повторную оценку данных, перестроить прогнозирующие модели или изменить само понимание анализируемых процессов.
Какой будет следующий этап зависит от результатов этапа. Стрелки указывают наиболее важные и частые зависимости между этапами. Внешний круг на рисунке указывает на цикличность процесса интеллектуального анализа данных. Процесс анализа данных продолжается даже после развертывания решения. Необходимо проводить мониторинг, насколько качественно модели справляются с изменяющейся реальностью.
Уточнения, полученные в ходе процесса, могут породить другие, более детализированные вопросы. Последующие итерации анализа данных, извлекают выгоду из предыдущих. Необходимо постоянное совершенствование моделей для того, чтобы они давали лучшие результаты и не устаревали.
Далее более детально остановимся на каждом этапе. По возможности приведу изображения из практических заданий и курса, чтобы было понятнее, как визуально выглядят результаты этапов.
Этап 1: Понимание бизнеса (Business Understanding Phase)
«Неполное понимание целей является важнейшей проблемой в любом техническом проекте — именно по этой причине удача обычно чаще сопутствует тем, кто начинает со скромных масштабов, а в дальнейшем наращивает их, опираясь на полученный опыт.» Билл Гейтс.
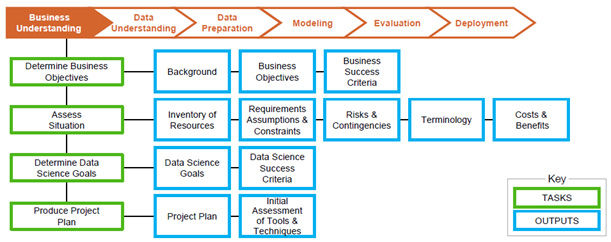
Рис. 6 Задачи и результаты этапа понимания бизнеса
Первый этап проекта состоит в определении целей проекта и требований со стороны бизнеса. Затем эти знания трансформируются в постановку задачи на анализ данных и предварительный план достижения целей проекта (Рис. 6).
Последовательность шагов этапа 1:
- Определить бизнес цели
- Оценить ситуацию
- Определить цели анализа данных
- Составить план проекта
Этап 2: Понимание данных (Data Understanding)
«Если думаешь, что тебе всё известно - ты чего-то не заметил» Томас Роберт Дьюар
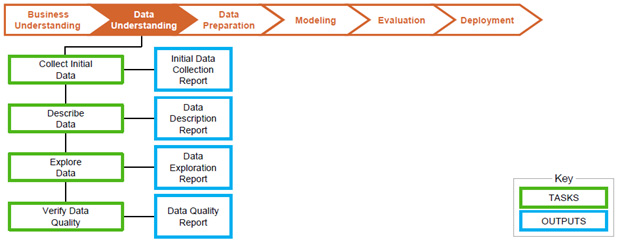
Рис. 7 Задачи и результаты этапа понимания данных
Второй этап начинается со сбора данных и ознакомления с данными. Необходимо понять какие данные у нас есть на входе, что означает тот или иной показатель, какова структура у данных. Проводится статистический анализ, выявляются выбросы,
Если хотите прочитать статью полностью и оставить свои комментарии присоединяйтесь к sapland
ЗарегистрироватьсяУ вас уже есть учетная запись?
Войти