Храним остатки. Решение для SAP BW
В статье описываются принципы проектирования Решения по хранению остатков по счетам в системе SAP BW. Наиболее важно при проектировании Решения - построить «правильную» модель. Приведён пример построения модели с интервальным хранением остатков и описаны возможности использования данной модели.
На базе баланса в коммерческом банке формируется множество отчетов, отражающих различные аспекты деятельности банка, таких как: балансовые показатели по различным банковским продуктам, динамику изменения остатков на счетах, ликвидность, покрытие активов пассивами и прочее.
Простые отчеты обычно строят на базе транзакционной системы. Но сложную аналитику необходимо «выносить» в отдельную систему – хранилище данных. При этом следует переносить данные в модель, которая оптимизирована для построения аналитики. Это снимает часть нагрузки с транзакционной системы, за счёт переноса формирования «тяжелых» отчётов на отдельный сервер.
Одной из первых задач, которая ставится при создании банковского хранилища данных – построение секции Главной книги. Основные объекты – счета и остатки из первичных систем, которые используются для получения баланса. Попробуем решить типичную задачу, с которой обязательно столкнутся специалисты, которые будут проектировать банковское хранилище данных для задач регуляторной и управленческой отчётности.
Итак, вводная. Банк из top 30, специализирующийся на розничном бизнесе, с разветвленной сетью филиалов решил внедрить хранилище на SAP BW. В банке 50 филиалов, помимо центрального офиса. Открыто 1.2 миллиона счетов, из них 800 тысяч имеют остаток, отличный от нуля. В течение операционного дня банка проходит, в среднем, 400 тысяч проводок, затрагивая 80 тысяч счетов в день. Объемы зависят от дня недели и месяца. Банк работает 6 дней в неделю, что составляет 306 рабочих дня в году.
Необходимо принять решение о том, как хранить обороты и остатки, чтобы удовлетворить следующим требованиям:
-
достаточно высокая скорость выборки;
-
грануляция данных до уровня движения по каждому аналитическому счету за каждый день;
-
возможность выверки и быстрого получения баланса за любой день;
-
учет изменений сальдо счетов в прошлых датах;
-
хранение остатков и оборотов как в валюте номинала счёта, так и в рублёвом эквиваленте;
-
обеспечение работы с данными, с помощью таких инструментов, как BEX и SAP Bussiness Objects;
-
обеспечение использования модели хранения данных в иных задачах.
Хранение записей об остатках
Так как проектируется OLAP система, то вопрос объема хранения данных стоит на последнем месте, а скорость выборки на самом первом. В то же время, слишком раздутые таблицы будут замедлять выборку по ним. Для каждого варианта напишу годовой прирост по записям (исходя из 306 рабочих дней) и оценки производительности.
1 вариант – храним остатки только за те дни, когда было движение по счету. Структура объекта:

Достоинства: маленький объем хранения, быстрая загрузка.
Недостатки: медленная выборка.
При выборе значений при помощи ABAP необходимо использовать выбор максимальной даты остатка, меньшей или равной текущей. В BEX – спецагрегацию “последнее значение остатка”. Годовой прирост: 306*80 тысяч = 24.6 млн. записей.
Достоинства этой схемы, нивелируются наличием оператора max при запросе к базе данных. Информация по одному остатку выбирается быстро. А вот построение срезов остатков будет работать довольно медленно, из-за того, что серверу базы данных необходимо полностью прочитать и просканировать первичный ключ таблицы.
2 вариант – храним декартово произведение - записи о каждом остатке по каждому счету ежедневно, даже если остаток не менялся. Структура объекта аналогична первому варианту.
Достоинства: быстрая выборка.
Недостатки: большой объем хранения, медленная загрузка.
Можно хранить рассчитанные валютные эквиваленты на каждый день, исключив тем самым, переоценку во время работы с остатками. Со временем начнутся проблемы с администрированием большой таблицы. Необходимо сразу делать партиционирование по датам на уровне базы данных и физически, на уровне табличного пространства. Запросы выполняются точно по ключу, без операций с диапазоном дат, что позволяет быстро выбирать остатки. Но необходимо хранить ежедневные остатки, даже за выходные дни, так как начало или окончание отчетного периода может попасть на воскресенье.
Годовой прирост 365*1,2 мил. = 438 млн. записей, если хранятся остатки за каждый день. Или 253*1,2 мил. = 303 млн. записей, если реализован механизм корректировки дат отчета на рабочие дни. Это число может быть ещё уменьшено, если не хранить нулевые остатки по неактивным счетам - объем хранения может снизиться ещё на 30%.
При таком объёме будет острой проблема потребляемого дискового пространства для хранения информации. Также сразу необходимо создавать регламент управления жизненным циклом данных и ограничивать максимальную глубину хранения информации.
3 вариант – храним диапазон действия остатка. Ключи:

Достоинства: маленький объем хранения, относительно быстрая выборка.
Недостатки: требуются дополнительные ресурсы при загрузке.
После загрузки остатков необходимо провести перерасчет временного ряда «ДАТА АКТУАЛЬНОСТИ ОСТАТКА С», «ДАТА АКТУАЛЬНОСТИ ОСТАТКА ПО», с датой открытия диапазона ’01.01.1000′, закрытия ’31.12.9999′. При выборе остатков необходимо ставить условие выборки по вхождению отчётной даты в диапазон действия да остатков. Этот вариант немного медленнее второго варианта, но не имеет его недостатков, связанных с ростом объема таблицы. Годовой прирост маленький, как и в первом случае.
Для выбора остатков необходимо конструировать запросы вида:
Выбрать ОСТАТОК из ОБЪЕКТА_ОСТАТКОВ, где ФИЛИАЛ = ИСКОМЫЙ_ФИЛИАЛ и СЧЕТ = ИСКОМЫЙ_СЧЁТ и ДАТА АКТУАЛЬНОСТИ ОСТАТКА С <= ЗАПРАШИВАЕМАЯ_ДАТА и ДАТА АКТУАЛЬНОСТИ ОСТАТКА ПО >= ЗАПРАШИВАЕМАЯ_ДАТА.
Такую модель хранения остатков автор использует под именем «Интервальные остатки». Модель оказалась оптимальной и используется мною в нескольких задач.
Типовая архитектура хранилища данных
Типичная упрощенная модель потока данных в хранилище представлена на Рис.1.
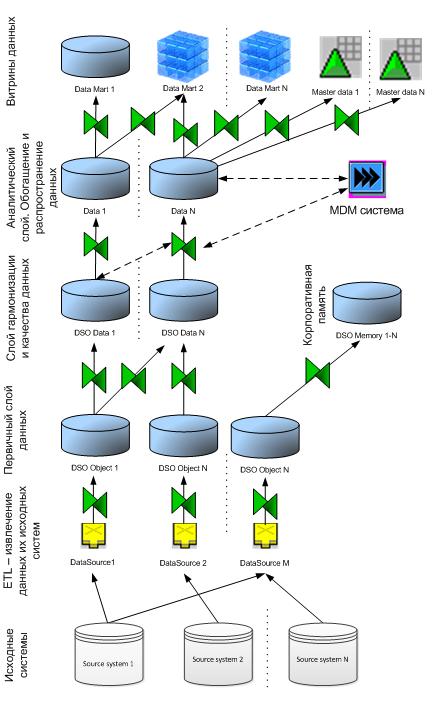
Рис.1 Упрощенная модель потока данных в хранилище
Обработка дублей информации в исходных данных и формирование дельты
Хранилище «живет» отдельно от основного операционного дня банка. Становится важным фактор отставания актуальности информации в хранилище от данных операционных систем. Объем информационной дельты, извлекаемой из исходных систем, может быть как дневной, так и 15-минутный. Всё зависит от необходимости в получении оперативных отчетов и допустимого запаздывания. Не всё программное обеспечение для ведения бухгалтерского учёта в банке может обеспечить выгрузку строго измененных остатков на счетах за последний период. Возможны дублирования одной и той же информации.
Если данные, содержащие дубли, сразу загружать в инфо-куб, то возникнет проблема с «задвоением» остатков. Поэтому здесь поможет DSO объект. За счет журнала изменений мы избавляемся от дублей в записях. Если на вход DSO подавать дубли данных, то на выходе в поток данных попадут только изменённые записи. Это свойство облегчает жизнь, когда исходная система не может обеспечить поставку дельты данных и необходимо загружать заведомо избыточный объём. Простая схема потока данных приведена на Рис.2.

Рис. 2 Простая схема потока данных
Дубликаты в информации фильтруются в DSO объекте. В инфо-куб по дельте попадают только изменённые и новые записи.
Для того, чтобы показать пример работы журнала DSO создадим стандартный DSO объект со структурой, описанной в третьем варианте (Рис.3).

Рис.3 Структура DSO объекта
Первичная загрузка (Рис.4).

Рис. 4 Первичная загрузка
Журнал изменений после первичной загрузки (Рис.5).

Рис. 5 Журнал изменений после первичной загрузки
При первичной загрузке все записи считаются новыми и сохранены в журнале с Recordmode = “N” (New-image).
Промоделируем ситуацию, когда по одному счёту произошло изменение остатка в прошлой дате, а по другому счёту был загружен дубликат с записью остатка (Рис.6).

Рис. 6
Из рисунка 6 видно, что по счёту 1120000000000 «пришел» дубликат записи с остатком, аналогичный загруженным ранее данным. По счёту 1110000000000 03.01.2012 был изменён оборот, что повлияло на остаток по счёту.
После активации новых данных таблица активных данных примет вид Рис.7.

Рис.7 Таблица активных данных
Красным цветом выделены изменённые записи.
В журнал изменений DSO будут добавлены такие записи (Рис.8)

Рис. 8
При активации данных в DSO объекте было определено, что запись по счёту 1120000000000 была дубликатом активных данных, записей изменений в журнале изменений сформировано не было. По счёту 1110000000000 было два изменения, для каждого их которых в журнале изменений было сформировано две строки. В первой строке с Recordmode = “X” (Before-Image) все показатели сохраняются со знаком минус для сторнирования существующей записи. Вторая строка с Recordmode = “ ” (After-Image), содержит новую версию данных.
Загружая данные в инфо-куб из журнала изменений DSO, мы избегаем ситуации с «задвоением» данных. Если запись с определённым ключом была изменена, то агрегация по сумме записей из журнала изменений DSO объекта возвратит значение, равное соответствующим значениям из таблицы активных данных. Проиллюстрируем это на примере, показав запись из таблицы активных данных и изменения к этой записи из журнала изменений DSO (Рис.9)


Рис. 9
Видно, что сумма показателей из журнала изменений DSO равна значению из активной записи: 101,00 – 101,00 + 103,00 = 103,00 значению показателей активной записи. Конечно, вместо одной активной записи в инфо-куб будут сохранены три записи – вся история изменений записи в DSO объекте. Но эта избыточность записей устраняется при сжатии инфо-куба с сокрытием нулевых записей.
Таким образом, работа журнала изменений DSO объекта существенно облегчает работу по устранению дублирования информации. Также подобная схема позволяет проводить «аналитическую раскраску» данных, хранящихся в DSO. Необходимые аналитики могут поступать с какой-то временной задержкой. Но для предложенной модели потока данных это не критично. Изменения какого-либо из признаков в DSO объекте породит корректную дельту для загрузки в инфо-куб.
Расчёт значения поля «Дата актуальности остатка, по»
В примере, приведённом выше, был получен объект, у которого дата действия остатка равна 31.12.9999. И достоинства решения, описанные в третьем варианте построения объекта, не используются. Необходимо создать функционал, который верно заполнит дату действия актуальности остатка.
Первым шагом создадим инфо-набор на базе DSO объекта REST_ACC. Данное действие позволяет избежать агрегации по показателям в SAP Netweaver 7.0 при считывании данных из DSO объекта. В последующих версиях есть возможность осуществлять выбор исходных полей трансформации инфо-набор можно не создавать.
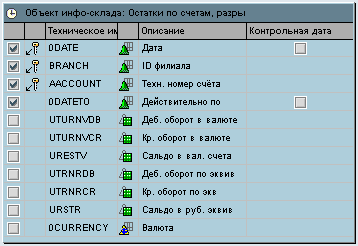
Рис. 10
Создадим трансформацию из инфо-набора REST_AC1 в DSO объект REST_ACC. Из правил трансформации оставим активными только поля ключа и атрибут даты действия 0DATETO

Рис. 11
В подпрограмму старта необходимо ввести код (для случая с инфо-набором):
data:
local_F1 TYPE /BI0/OIDATE, " Дата
local_F2 TYPE /BIC/OIBRANCH, " ID филиала.
local_F3 TYPE /BIC/OIAACCOUNT, "Техн. номер счёта.
local_date_to TYPE d.
" Сортируем пакет по филиаду-счёту и убыванию даты
sort SOURCE_PACKAGE by F2 ASCENDING
F3 ASCENDING
F1 DESCENDING.
LOOP AT SOURCE_PACKAGE ASSIGNING <SOURCE_FIELDS>.
if <SOURCE_FIELDS>-F2 <> local_F2
or <SOURCE_FIELDS>-F3 <> local_F3.
local_F2 = <SOURCE_FIELDS>-F2.
local_F3 = <SOURCE_FIELDS>-F3.
local_date_to = '99991231'.
endif.
IF <SOURCE_FIELDS>-F4 = local_date_to.
local_date_to = <SOURCE_FIELDS>-F1 - 1.
DELETE SOURCE_PACKAGE.
CONTINUE.
ELSE.
<SOURCE_FIELDS>-F4 = local_date_to.
local_date_to = <SOURCE_FIELDS>-F1 - 1.
ENDIF.
ENDLOOP.
Здесь в ABAP реализован простой функционал, который сортирует записи по каждому сочетанию «филиал + счёт» по дате убывания. После сортировки в начале списка оказывается самая последняя запись, дата действия у которой фиксирована 31.12.9999, затем «просматриваются» остальные записи и каждой последующей присваивается дата действия равная дате операции из предыдущей записи минус 1 день.
После работы трансформации получаем 3 изменения в таблицу новых данных DSO объекта.

Рис. 12
Поля с суммами не заполнены, так как они были исключены из обновления в трансформации. После активации данных получаем таблицу активных данных в таком виде (Рис.13).

Рис. 13
Видно, что произошло обновление поля даты актуальности остатка. Теперь для выбора информации об остатке необходимо использовать две даты актуальности. Такой запрос к базе данных «легче», чем выбор максимальной даты изменения остатка, меньшей или равной дате отчёта. Разумеется, что после изменения 3-х строк будет сгенерировано 6 строк в журнале изменений DSO объекта
Обеспечение дельты и корректировки в прошлых датах
Данные в таблицах DSO хранятся в развернутом виде. Это облегчает отладку загрузки, позволяет визуально сравнивать отчеты и строить запросы стандартными SAP GUI средствами, быстрее, чем через просмотр данных инфо-куба.
Но DSO сильно хромает в плане производительности при использовании в отчётах. OLAP запросы лучше строить на инфо-кубах. Поэтому необходимо реализовать загрузку из DSO в инфо-куб. Предпочтительно сделать инфо-куб по структуре точно таким же, как DSO. Это позволит безболезненно переносить отлаженные BEX запросы из DSO на инфо-куб. Единственная возможная проблема – отсутствие инфо-объекта 1rownum в инфо-кубе, который отражает число агрегированных записей в строке. Но это решается созданием в системе показателя, куда будет присваиваться константа 1 в DSO, а работа механизма агрегация в инфо-кубе позволит заменить стандартный 1rownum.
Также актуальна проблема проводок задним числом, особенно в начале календарного периода. Хранилище загружает информацию об остатках и обновляет послойно информацию в модели данных хранения остатков. Российский учёт позволяет проводить корректировки баланса в прошлых датах при незакрытом отчётном периоде. Также проблем добавляет работа банка в нескольких часовых поясах. Когда во Владивостоке уже начато обслуживание клиентов в следующем операционном дне банка, в Москве происходит закрытие баланса и начисление процентов. Поэтому, загрузка остатков, к примеру, строго в 2 часа ночи не даёт гарантии, что в этом операционном дне не будет ещё проводок.
Это порождает множество проблем с пересчётом остатков, изменённых в прошлых периодах и корректного отражения их в схеме данных. Необходимо обеспечить наличие в витринах данных прошлой версии информации и корректный расчёт новой версии, которая добавит к предыдущей версии необходимую дельту для корректного перехода в новую версию данных, актуальную на данный момент времени. Обычно эту проблему отдают на сторону ETL процесса.
Потенциал для увеличения производительности
В старых версиях SAP NetWeaver таблицу активных данных DSO объекта можно переопределить на уровне БД, добавив принудительное партиционирование по диапазону какого-либо значения. Но здесь можно рассчитывать на ощутимый прирост, только если физически данные будут храниться на разных дисковых массивах. Сейчас практически везде используется единый большой RAID, который и так обеспечивает размазывание данных по нескольким дискам. Поэтому партиционирование становится как бы ещё одним индексом.
Стоит обратить внимание на партиционирование таблицы фактов в инфо-кубе на уровне БД. Необходимо использовать стандартное разделение по атрибуту времени.
Ещё одним способом ускорить выборки является физическое разбиение данных по нескольким инфо-кубам и объединение их в мультипровайдер. Этот путь имеет хороший потенциал для оптимизации и экспериментов. Помимо стандартного разбиения по календарным годам/кварталам/месяцам можно подумать и разбить, к примеру, по балансовым счетам.
В SAP NetWeaver BW 7.3 добавляется новый тип объектов – семантически партицированные провайдеры, которые облегчили разбиение больших объектов на отдельные провайдеры данных.
Подобная оптимизация добавляет 7-15% к скорости извлечения данных.
Анализируя банковские полупроводки можно прийти к выводу, что ряд балансовых счетов встречаются в корреспонденции наиболее часто. К примеру, транзитные счета могут встречаться при проводках, выгружаемых из внешних систем, для массовых платежей. В отдельных случаях движения по таким балансовым счетам может составлять до 30% от общего числа. Это делает неэффективным выборку по балансовым счетам, к примеру, в головном банке и такая картина не наблюдается в остальных филиалах. Если разделить такие остатки по различным инфо-кубам, сделать сепарацию по балансовым счетам, то тот же Oracle более качественно соберет статистику по таблицам. В итоге это опять же повлияет на общую производительность. Имеет смысл дробить разделение вплоть до ограничения данных под группу конкретных отчетов.
Но всё же, стоит понимать, что любые подобные “улучшения”, увеличивающие скорость выборки, в итоге замедляют саму загрузку данных, усложняют процесс моделировании и мониторинг системы. Поэтому необходимо искать некий оптимум в каждом случае.
Использование схемы хранения с интервальными остатками для расчёта среднемесячных остатков
Для целей финансовой аналитики очень часто встаёт задача расчёта среднего остатка на счёте. К примеру, это может понадобиться в задаче определения трансферной стоимости денежных ресурсов или для построения аналитики по остаткам на счетах «до востребования». Модель с интервальными остатками позволяет достаточно изящно решить эту задачу.
Создадим DSO объект для хранения средних остатков (Рис.14).
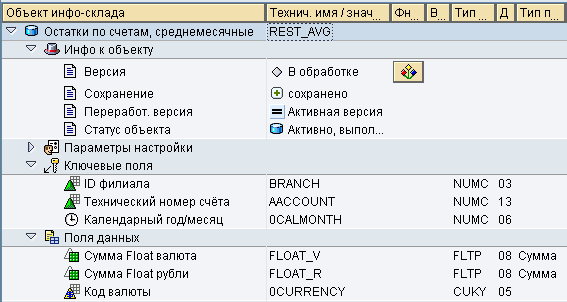
Рис. 14
Поля хранения среднего остатка необходимо типизировать как float. Использование типа DEC может приводить к расхождениям в несколько копеек при агрегации движения по счетам с большим числом операций и периодическими обнулениями.
Создадим промежуточную структуру – инфо-источник, скопировав поля созданного DSO объекта, а также добавив поле счётчика. Счётчик необходим для построения двухэтапной трансформации, когда на первой трансформации могут быть сгенерированы записи с аналогичным ключом и необходимо провести агрегирование на втором этапе трансформации.
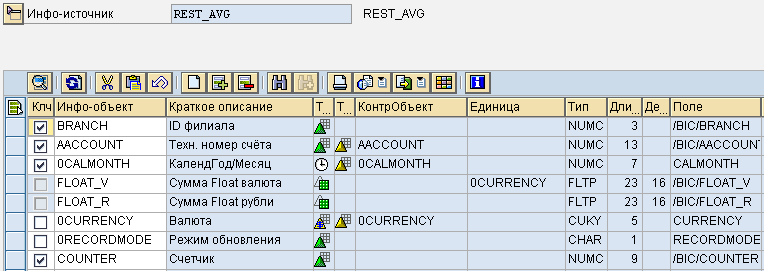
Рис. 15
Соединим DSO REST_ACC c DSO REST_AVG через инфо-источник REST_AVG, чтобы получить поток данных, приведённых на рисунке:
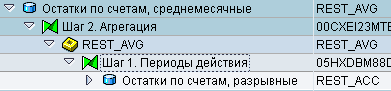
Рис. 16
Необходимо модифицировать первый шаг трансформации, изменив тип на экспертную подпрограмму (expert routine). В результате получим преобразование, изображенное на рисунке:

Рис. 17
В текст экспертной подпрограммы впишем следующий текст:
types: begin of stru, " структура периодов
CALMONTH TYPE /BI0/OICALMONTH,
first_day TYPE d,
last_day TYPE d,
count_day TYPE i,
end of stru.
data: it_CM type table of stru,
wa_CM type stru,
RECORD
Если хотите прочитать статью полностью и оставить свои комментарии присоединяйтесь к sapland
ЗарегистрироватьсяУ вас уже есть учетная запись?
Войти
Обсуждения 3
3
Комментарий от
Илья Муковоз
| 21 мая 2013, 14:21
Андрей, не увидел в вашем материале как вы обрабатываете изменения в заднем числе и проводки задним числом.
Комментарий от
Андрей Ржаксинский
| 23 мая 2013, 08:42
Илья Муковоз 21 мая 2013, 14:21
То-то я смотрю, имена объектов знакомые ;)
Андрей, не увидел в вашем материале как вы обрабатываете изменения в заднем числе и проводки задним числом.
Изменения остатков в задних числах фиксируются на уровне ETL. На вход поступают все остатки за каждый день с момента изменения в прошлой дате.
Мы отказались от расчёта остатков из проводок, как было в предыдущем решении. Вместо этого проводится контроль между оборотами по счетам, поступающих из структуры остатков и оборотами, собираемыми из проводок. Выполняется загрузка этих данных в куб с противоположными знаком. Агрегация данных в кубе сразу позволяет выявлять расхождения по дням по каждому счёту. Данный куб используется как средство внутреннего контроля Главной книги внутри BW.
Комментарий от
Илья Муковоз
| 23 мая 2013, 15:47
Андрей Ржаксинский 23 мая 2013, 08:42
Илья.
Изменения остатков в задних числах фиксируются на уровне ETL. На вход поступают все остатки за каждый день с момента изменения в прошлой дате.
Мы отказались от расчёта остатков из проводок, как было в предыдущем решении. Вместо этого проводится контроль между оборотами по счетам, поступающих из структуры остатков и оборотами, собираемыми из проводок. Выполняется загрузка этих данных в куб с противоположными знаком. Агрегация данных в кубе сразу позволяет выявлять расхождения по дням по каждому счёту. Данный куб используется как средство внутреннего контроля Главной книги внутри BW.