DataMining в SAP: используем модель дерево принятия решений
Данная статья расскажет о возможностях SAP по анализу данных на примере построения модели дерева принятия решений. Соответствующая функциональность встроена в платформу SAP Netweaver и по умолчанию присутствует во всех системах. Рассматривается простой пример анализа данных и извлечения знаний. Приводится анализ возможности использования полученных знаний при запуске маркетинговых кампаний в ритейле.
Ржаксинский Андрей выполняет обязанности PM проекта построения хранилища SAP BW в Промсвязьбанке, Москва, где работает с 2009 г. Занимается развитием и архитектурой хранилища. Более 8 лет специализируется на внедрении решений SAP в банках. Электронная почта - sapforbanking@gmail.com. Персональный блог о SAP в банках - sapbanking.org.
Деревья приятия решений
При построении дерева принятия решений используется один из алгоритмов классификации и разделения данных. Основой для построения дерева решений является обучающий набор данных, представляющий собой набор атрибутов, характеризующий некую сущность и известный исход события, связанный с данной сущностью.
Сегментация осуществляется с целью объединения в группы прецедентов с одинаковыми вероятностями исхода. Сегментация данных происходит путем последовательного дробления пространства данных на области с фиксированными границами. Критериям разделения при построении дерева решений является различие в соотношении положительных и отрицательных исходов событий. Обучение прекращается, когда дальнейшее дробление на более мелкие группы не приводит к значимому различию этого соотношения. Предполагается, что обучающая выборка является репрезентативной и, с определенной погрешностью, может прогнозировать исход для новых наборов данных.
Построенное дерево решений является исходным материалом для Data Mining – «извлечения знаний». Оно позволяет визуализировать полученные закономерности в понятном виде.
Практическое применение данного алгоритма – кредитный скоринг, анализ поведения клиентов.
Использование
Рассмотрим, как можно извлечь закономерности и построить правила (дерево принятия решения) из исходного пула информации. Выявим наиболее значимые факторы, влияющие на принятие решений конкретной группой людей, потребителей товаров и услуг.
Из исходного набора данных извлечем информацию о том, как прогнозное поле зависит от значения исходных данных, найдем закономерности в данных и опишем их словами. Это позволит кластеризировать (разбить на сходные подмножества) исходные данные, выделить сегменты потребителей, наиболее чувствительные к влиянию рекламы. На основании полученных данных можно будет снизить издержки маркетинговых кампаний, сконцентрировав усилия на донесении информации конкретным группам потенциальных клиентов.
При этом, какие именно совокупности данных (возраст, пол, регион, доход, используемые продукты, вид занятости и прочее) анализируются, не имеет особой разницы. Главное, чтобы эти данные были полны и достоверны. . Необходимо ранжировать и группировать исходные данные. К примеру, возраст можно разделить на социальные группы и закодировать одним значением, к примеру, 16-22 года – студенты ведут себя примерно одинаково. По мере наполнения и улучшения статистической базы, появится возможность исследовать конкретную возрастную группу и сделать более мелкие диапазоны для анализа. То есть анализ идет от более крупной агрегации к получению более детализированной картины.
Эффективным является использование описанного подхода при запуске кампании по предложению нового продукта в отдельном пилотном регионе или случайно выбранным клиентам. Сегментация полученных данных позволит выбрать клиентские сегменты, лояльно настроенные к предлагаемому продукту. При этом, основная маркетинговая кампания уже будет направлена на определенную целевую аудиторию. Идеальный вариант использования таких моделей – это наличие постоянной обратной связи, которая позволит анализировать результаты каждой маркетинговой кампании.
Наличие обратного потока информации позволит проводить создание («обучение») новых моделей, видеть результаты пилотных запусков продаж. Могут быть выявлены новые закономерности, в принципе неразличимые на тестовой выборке, но появившиеся при повторном прогоне модели.
Необходимо стремиться к уменьшению объема целевой группы для каждой маркетинговой кампании, одновременно увеличивая эффективность кампании, акцентируя внимание на клиентах с наибольшим потенциалом. Постепенно следует расширять число моделей и улучшать их качество: готовить модели, которые учитывают специфику конкретного региона и / или уникальные знания экспертов.
Преимущества использования дерева построения решений в том, что алгоритм расчёта позволяет задать показатели для принятия решений. В одной клиентской группе более важен вид занятости и возраст, в другой – доход, в третьей – имеет ли клиент кредит в банке. И значит, для каждой группы клиентов можно построить «своё» дерево принятия решений, которое опишет предпочтения анализируемого потребительского сегмента наиболее полно. Будут определены наиболее эффективные каналы донесения информации клиенту – реклама, обзвон, рассылка по почте, рассылка SMS, прямые продажи в офисе, кросс-продажи.
Кампания, реализованная на основе анализа дерева построения решения, даст следующие результаты:
- увеличение прибыльности бизнеса;
- увеличение соотношения числа продаж к числу контактов с клиентами;
- увеличения числа повторных продаж, кросс-продажи;
- увеличение лояльности;
- уменьшение расходов на рекламные кампании через повышение эффективности кампаний;
- снижение затрат на обзвон и SMS информирование из-за уменьшения объемов целевых групп;
- он-лайн контроль эффективности рекламных кампаний, поиск наиболее эффективных маркетинговых программ, коррекция кампаний;
- снижение расходов благодаря отказу в продаже заведомо “провальных” продуктов заведомо нелояльным категориям клиентов, возможно отказ от таких клиентов;
- набор статистической информации для построения воронки продаж и анализа пути превращения потенциального клиента в реального;
- снижение оттока клиентов.
Реализация в SAP
В платформу SAP NetWeaver встроено как хранилище данных SAP BW, так и инструменты анализа данных. Далее на простом примере будет показана реализация анализа данных этим стандартным инструментарием.
В качестве исходных данных взят файл, поставляемый в папке с примерами к среде анализа данных SPSS Clementine 12.0. Сейчас более новая версия этого инструмента входит в линейку продуктов SAP под названием SAP BusinessObjects Predictive Workbench.
В исходном файле содержатся результаты некоего виртуально исследования в количестве 482 фактов. Этого количества достаточно, чтобы продемонстрировать возможность извлечения знаний.
Исходный файл содержит такие поля:
- EDUCATE – число лет образования;
- GENDER – пол;
- AGE – возраст;
- TVDAY – среднее число часов просмотра TV в день;
- ORGS – кодированная принадлежность к какой-либо организации;
- CHILDS – количество детей;
- INC – Income category – уровень дохода клиента;
- NEWSCHAN – подверженность влиянию новостей/рекламы – это прогнозное поле, на основании которого обучается модель.
Вот пример исходных данных из файла в формате CSV:
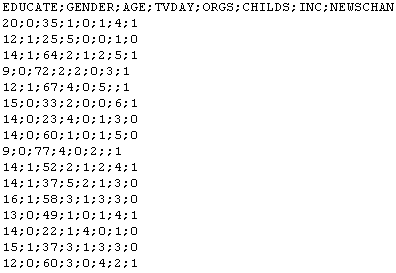
Загрузим эти данные в аналогичный по структуре DSO:
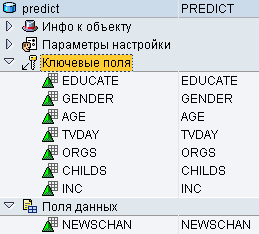
В транзакции «RSA1 - Моделирование - ИнстрСредства DW» проведем моделирование необходимого процесса загрузки. Первым шагом создадим источник данных BW в исходной системе, предназначенной для работы с файлами. В данном случае PCFILE.
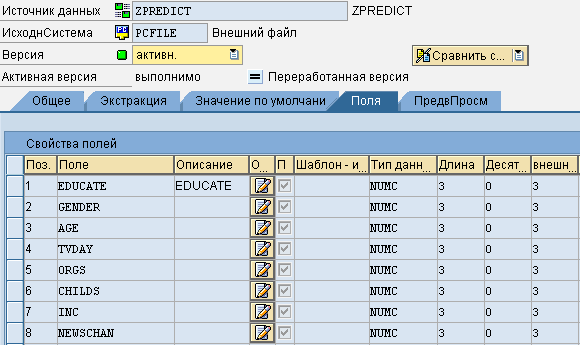
Затем необходимо создать инфопакет, который загрузит данные из файла в PSA. В параметрах требуется указать разделитель CSV файла и то, что данные имеют переменную длину.
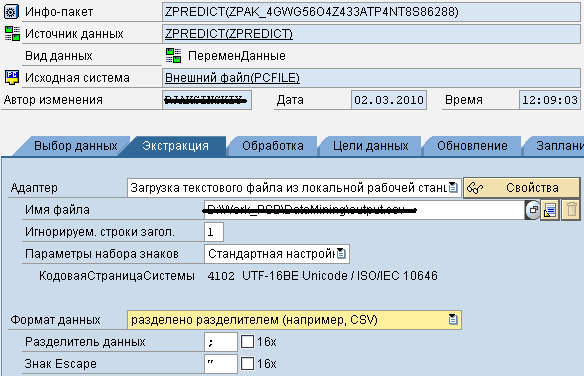
Следующий шаг – создание трансформации и процесса переноса данных. Трансформация данных простая -
Если хотите прочитать статью полностью и оставить свои комментарии присоединяйтесь к sapland
ЗарегистрироватьсяУ вас уже есть учетная запись?
Войти