Создание модели анализа социальных сетей в SAP Predictive Analytics*
Детально на конкретном примере описывается процесс создания модели анализа социальных сетей.

SAP Predictive Analytics
The Comprehensive Guide
Antoine Chabert, Andreas Forster, Laurent Tessier, Pierpaolo Vezzosi
![]()
Освойте прогностические модели — регрессию, прогнозирование временных рядов, кластеризацию и т. п. Узнайте, как установить и запустить SAP Predictive Analytics. Откройте для себя необходимые инструменты, от Predictive Factory и Automated Modeler до Data Manager и Social Network Analysis.
*Оригинал (англ.): SAP Predictive Analytics. The Comprehensive Guide. Антуан Шабер, Андреас Форстер, Лоран Тессиер, Пьерпаоло Веццози. Издательство SAP PRESS. Глава 12 (раздел 12.3). 2018, с. 306–323.
Корректура: Евгений Баранов (САПРАН).
Создание модели анализа социальных сетей
в SAP Predictive Analytics // SAP Professional Journal Россия, ноябрь–декабрь, №6 (77), стр. 93–126. @ 2019, Антуан Шабер, Андреас Форстер, Лоран Тессиер, Пьерпаоло Веццози.
Детально на конкретном примере описывается процесс создания модели анализа социальных сетей.
Теперь можно попробовать создать модель анализа социальных сетей. В этом разделе можно выполнять пошаговые действия, используя образцы наборов данных из этой книги или свои собственные данные, или же образцы данных, включенные в установленный экземпляр SAP Predictive Analytics Automated Analysis, находящиеся в каталоге ../../../Samples/KSN.
Образец данных анализа социальных сетей и рабочий процесс
Данные, используемые в этом примере, представляют собой упрощенную выборку группы людей, у которых были телефонные разговоры.
Образец набора данных можно загрузить по адресу www.sap-press.com/4491. Набор данных содержит четыре файла.
- Журнал исходящих звонков по номеру телефона (SNA_Calls.csv).
- Идентификатор клиента и его номер телефона (SNA_Lookup.csv).
- Информация из CRM-системы по каждому клиенту (SNA_Population.csv).
- Набор данных приложения (SNA_Apply.csv).
Данные содержат журнал телефонных звонков между двумя семьями с 1 января 2017 года по 28 февраля 2017 года. Два человека (Мэри и Джейн) из двух разных семей разговаривают друг с другом, как показано на Рис. 12.1.
Набор данных содержит только данные о телефонных звонках. Информация о двух семьях отсутствует. Данные будут использованы в модуле анализа социальных сетей для определения, кто кому звонил, и для поиска сообщества. Задача модуля анализа социальных сетей определить эти две отдельные семьи и выявить роли Джейн и Мэри.
В нашем наборе данных мы смоделировали, что Мэри изменила свой номер телефона и фигурирует для внешнего наблюдателя как два разных узла. Чтобы (заново) определить, что эти два узла в действительности являются одним и тем же человеком, в ходе анализа социальных сетей будет использована функция сопряжения узлов.
Для следующих этапов все три файла с примерами должны быть сохранены на вашем компьютере в каталоге C:\Predictive.
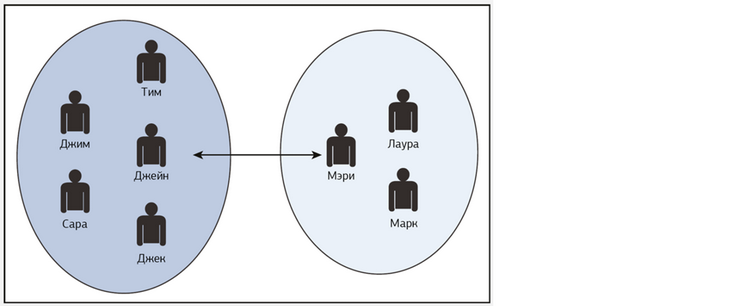
Рис. 12.1. Образец набора данных: журнал телефонных звонков между двумя семьями
Чтобы создать модель анализа социальных сетей, выполните следующие действия:
- Загрузите набор данных (или подключитесь к нему).
- Выберите тип создаваемого графа.
- (Опционально) Проведите более детальный анализ графа.
- Укажите, какой дополнительный анализ нужно выполнить (сообщества, мега-хабы, сопряжение узлов).
- Добавьте дополнительную информацию к социальным данным и начните построение. Приступим!
Запуск модуля и импорт набора данных (раздел 12.3.1)
Чтобы начать работу с графами, запустите интерфейс Automated Analytics (Автоматический анализ), перейдите в раздел Social (Социальный) и выберите модуль Create Social Network Analysis (Создать анализ социальной сети).
Откроется страница Add Graph (Добавить граф) (Рис. 12.2), где нужно выбрать Build a Social Graph From a Dataset (Построить социальный граф из набора данных). Два других параметра позволяют расширить существующий граф в другой модели (Extract a New Social Graph… (Извлечь новый социальный граф...)) или из двустороннего графа этой модели (Derive Graph from a Bipartite Graph (Получить граф из двустороннего графа)).
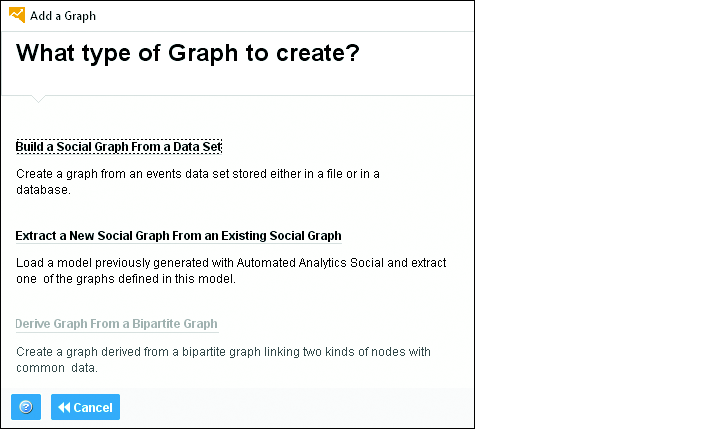
Рис. 12.2. Добавление нового социального графа в модель
Извлечение графа из другой модели полезно, если нужно построить модель на основе существующей модели для дополнительного уточнения. Получение графа из двустороннего графа используется для создания рекомендаций, процедура подробно описана в Главе 13.
Теперь выберите файл, который содержит отношения между вашими узлами, для нашего сценария это файл SNA Calls.csv, как показано на Рис. 12.3.
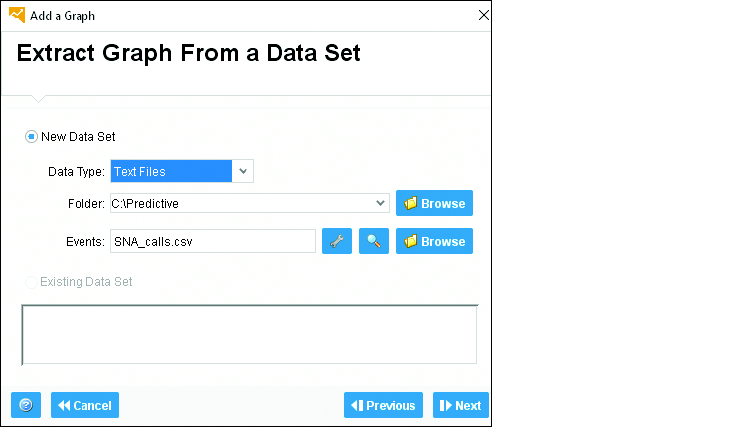
Рис. 12.3. Загрузка данных о событиях
Процесс загрузки данных аналогичен процессу, описанному в Главе 11, к которой необходимо обратиться за списком всех функций загрузки данных интерфейса. Обратите внимание, что вы можете получать данные не только из файлов, но и из таблиц базы данных.
Нажмите на кнопку с изображением лупы. Вы увидите следующую информацию о структуре данных (Рис. 12.6):
- источник: номер телефона звонящего;
- цель: номер телефона принимающего звонок;
- продолжительность: продолжительность общения в минутах;
- дата: дата звонка.
Как упоминалось в Главе 11, Раздел 11.2.1, можно посмотреть статистику по анализируемому набору данных. Обратите внимание, что поле Дата интерпретируется как строка, поскольку формат даты не является значением по умолчанию (см. Рис. 12.4), ожидаемым SAP Predictive Analytics (ГГГГ-ММ-ДД).
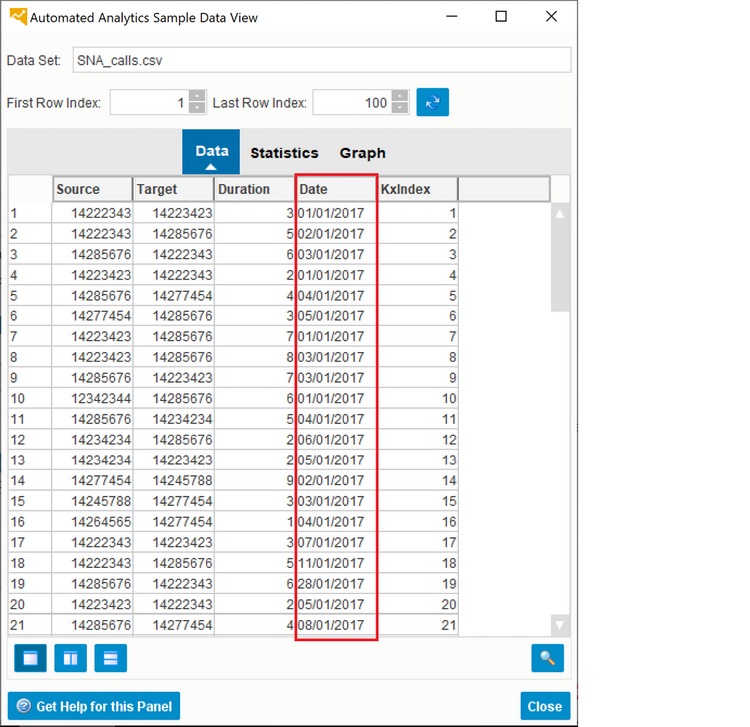
Рис. 12.4. Проблема с форматом данных поля Date
Чтобы изменить настройки по умолчанию, нажмите кнопку с гаечным ключом и измените настройки файла (Рис. 12.5.); введите косую черту «/» в поле разделителя даты и выберите Day Month Year из раскрывающегося списка Date Order (Формат даты). Если вы снова посмотрите статистику, обратите внимание, что поле даты интерпретировано правильно.
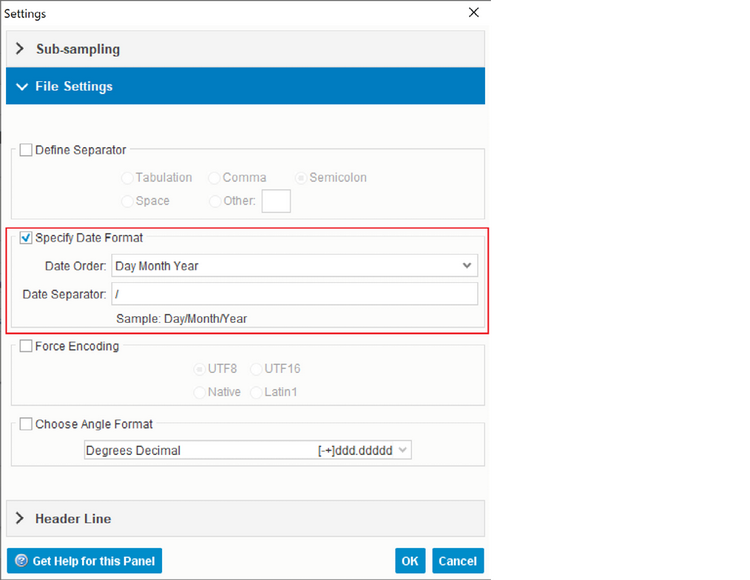
Рис. 12.5. Корректировка формата даты стандартными средствами
Перейдите на следующую страницу и нажмите кнопку Analyze (Анализировать), чтобы правильно интерпретировать набор данных для анализа. Откроется экран, показанный на Рис. 12.6.
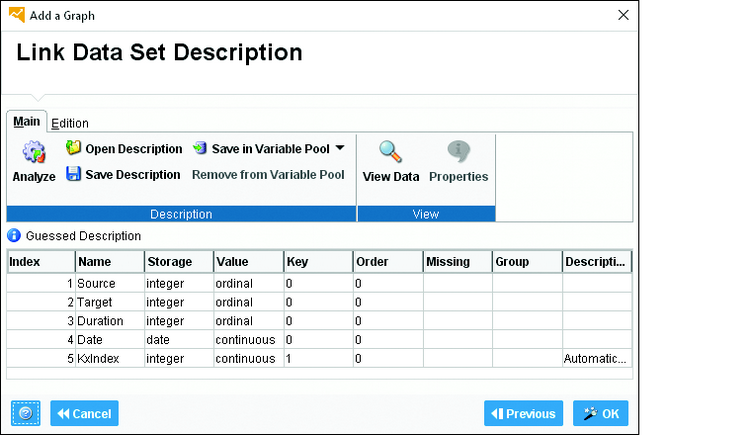
Рис. 12.6. Страница Link Data Set Description (Описание набора данных связи)
Теперь войдите в специальный интерфейс анализа социальных сетей, нажав кнопку ОК.
Назначение модели графа для построения (раздел 12.3.2)
После того как вы определили структуру данных, откроется страница Graph Definitions (Характеристики графа), как показано на Рис. 12.7.
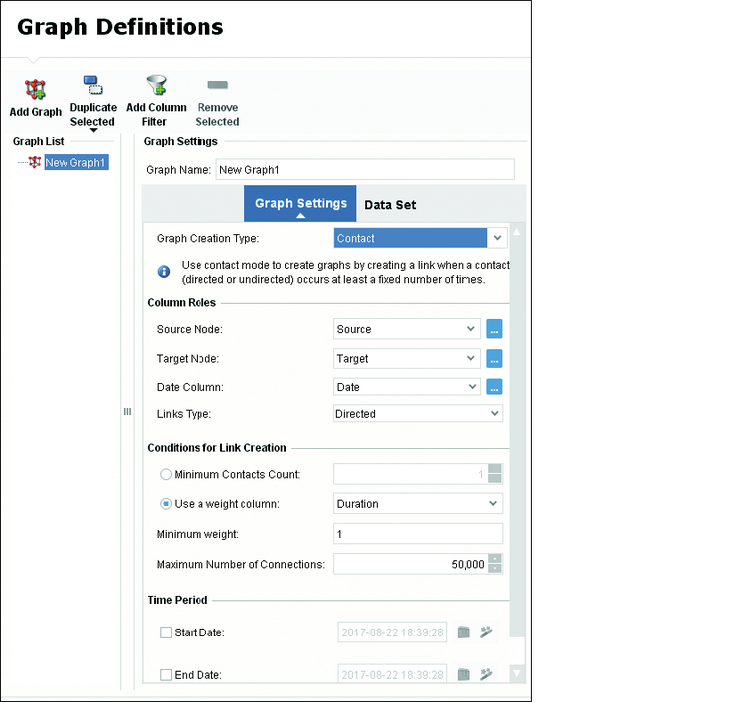
Рис. 12.7. Страница Graph Defi nitions (Характеристики графа)
Давайте познакомимся с интерфейсом:
- В левом верхнем углу элемент Graph List (Список графов) содержит все графы, которые будут сгенерированы. По умолчанию имя графа — New Graph1. Вы можете добавлять новые графы, дублировать существующие или фильтровать графы, используя кнопки на ленте или нажав правой кнопкой мыши на соответствующем графе. В Разделе 12.3.3 будет показано, как использовать функцию Temporal Duplication (Временное дублирование), но она в интерфейсе пока неактивна.
- Правая панель Graph Settings (Настройки графа) позволяет определить тип и содержание графа. По настройкам этой панели SAP Predictive Analytics определяет, как построить граф.
Можно создать пять различных типов графов (их описание приведено в Табл. 12.2). Выберите тип в раскрывающемся списке Graph Creation Type (Создание типа графа) (см. Рис. 12.8).
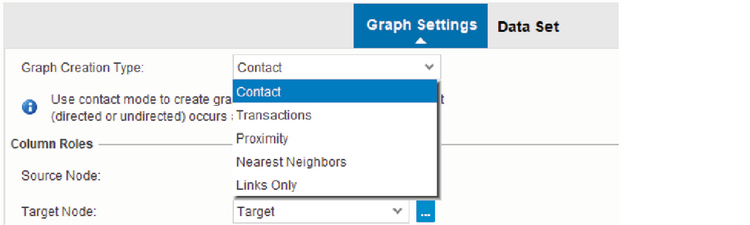
Рис. 12.8. Выбор типа построения графа

Табл. 12.2. Пять типов графов
Для нашего примера выберите тип графа «Контакт» и заполните страницу настроек графа, как показано на Рис. 12.7. Описания всех полей приведены в Табл. 12.3.
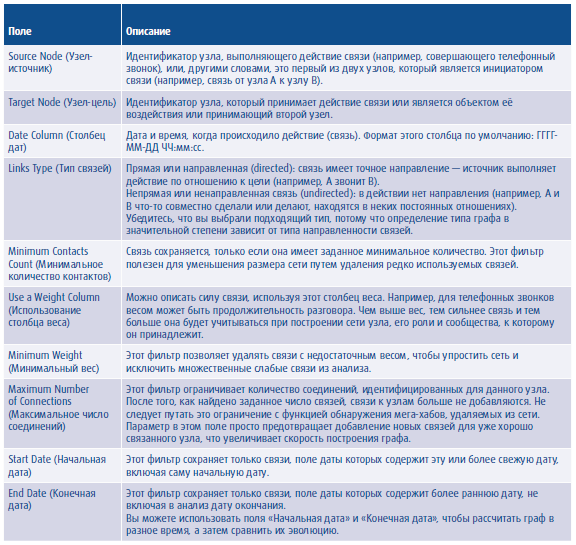
Табл. 12.3. Поля для определения графа контактов
Таким образом, введя данные для первого графа, уже можно приступить к анализу. Однако, в рамках нашего примера мы создадим другие графы, основанные на метках времени, чтобы можно было проанализировать их эволюцию.
Добавление графов (раздел 12.3.3)
Теперь мы продублируем существующий граф, затем отфильтруем дубликаты по определенному периоду времени, в результате чего будут автоматически построены другие графы для разных периодов времени. Цель нашего сценария — построить 4 двухнедельных графа и 2 ежемесячных графа.
Сначала нажмите New Graph1 на панели Graph List (Список графов), а затем в ленте выберите Duplicate Selected (Дублировать выбранный) • Clone (Клонировать). В списке появится копия графа. Для удобства чтения давайте переименуем граф, например, в «Temporal».
Перейдите к фильтрам периода времени и установите начальную дату 1 января 2017 года, а конечную дату — 15 января 2017 года. Страница Graph Settings (Настройки графа) должна выглядеть, как показано на Рис. 12.9; все остальные поля будут иметь такие значения, какие показаны на Рис. 12.7.
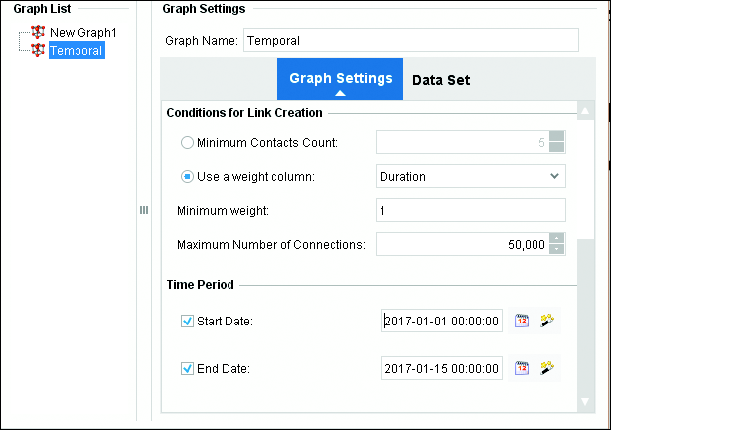
Рис. 12.9. Граф, отфильтрованный по дате
Теперь можно автоматически построить другой граф (по одному на каждые 2 недели), выбрав граф Temporal на странице Graph List (Список графов), а затем в ленте выбрав Duplicate Selected (Дублировать выбранные) • Temporal Duplication (Временное дублирование). В появившемся небольшом всплывающем окне установите значения для построения 3-х дополнительных графов по 14 дней каждый, чтобы охватить имеющиеся у нас данные за 2 месяца. ещё три графа будут созданы автоматически, как показано на Рис. 12.10.
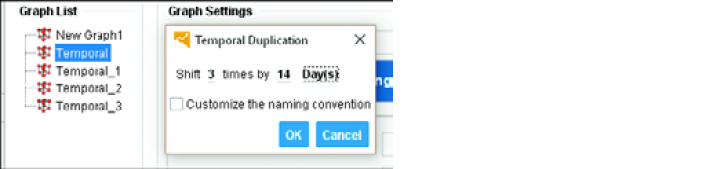
Рис. 12.10. Создание временного дубликата графа
Если вы проверите каждый граф, вы увидите, что его даты начала и окончания были автоматически сгенерированы со сдвигом 14 дней для каждого графа.
Выполните ту же последовательность действий, чтобы построить новый граф с 1 января по 31 января 2017 года, а затем используйте дублирование времени для создания графа за февраль. Графы нужно назвать JanuaryGraph и FebruaryGraph, соответственно.
В итоге граф New Graph1 будет содержать все записи телефонных звонков, которые у нас есть. Временные графы будут содержать по 14 дней разговоров каждый. JanuaryGraph будет содержать все звонки за январь, а FebruaryGraph — за февраль.
В этом интерфейсе вы также можете добавить фильтр социальных данных для определенного набора. Например, если в наборе данных есть информация о типе контакта (SMS, телефонный звонок, видеозвонок), вы можете создать конкретные графы для каждого из этих типов. Чтобы установить фильтр, выберите граф и нажмите кнопку Add Column Filter (Добавить фильтр столбцов) на ленте. Обратите внимание, что этот фильтр удаляет строки данных, но не удаляет отфильтрованный столбец. В нашем примере вам не нужно применять фильтры к образцу.
Теперь, когда вы определили, какие графы нужно создать, нажмите кнопку Next (Далее), чтобы перейти к этапу постобработки.
Настройка обнаружения сообществ, мега-хабов и сопряжений узлов (раздел 12.3.4)
После этапа определения графа нужно выбрать, какую дополнительную информацию вы хотите извлечь из существующих отношений. Страница Post-Processing (Постобработка) (Рис. 12.11) позволяет выбрать графы, в которых требуется обнаружить сообщества и мега-хабы.
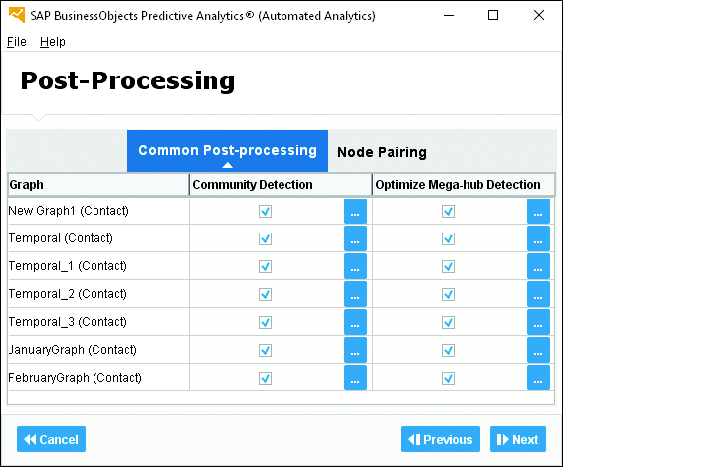
Рис. 12.11. Страница Post-Processing (Постобработка): настройка обнаружения сообществ и мега-хабов
По умолчанию сообщества и мега-хабы обнаруживаются во всех графах, что может быть действительно полезно, но часто отнимает много времени. В моделях, работа которых занимает много времени, рассмотрите возможность отключения или ограничения обнаружения сообществ (но сохраняйте удаление мега-хабов). Обнаружение включается и выключается установкой или снятием флажка в каждом поле. Нажимая на кнопку с троеточием ![]() рядом с каждым полем, можно точно настроить алгоритм обнаружения.
рядом с каждым полем, можно точно настроить алгоритм обнаружения.
Обнаружение сообществ производится посредством итерационного алгоритма (алгоритм Лувена), который находит узлы с наибольшим количеством взаимных связей. На каждой итерации приложение измеряет усиление кластеризации, представленное значением Эпсилон. Эти подробности об алгоритме, в целом, изучать не обязательно, однако специалистов по данным они могут заинтересовать.
Оформите подписку sappro и получите полный доступ к материалам SAPPRO
Оформить подпискуУ вас уже есть подписка?
Войти
