Методы сжатия баз данных
В статье речь пойдет о легких и тяжелых схем сжатия, которые могут быть применены к столбцам базы данных.
Введение
Крупнейшие в мире базы данных обрабатывают объемы до нескольких петабайт. Несмотря на возрастающие возможности и постоянное удешевление оперативной памяти, хранить в ней такие объемы все еще очень дорого. Таким образом, современные базы данных нуждаются в применении разнообразных методов сжатия.
Базы данных с колоночным хранением особенно хорошо подходят для сжатия, поскольку данные одного типа хранятся в них последовательно и по секциям. Это позволяет использовать специально созданные алгоритмы сжатия для определенных типов данных.
Перейдем к описанию легких и тяжелых схем сжатия, которые могут быть применены к столбцам базы данных.
Легкое сжатие (Light-Weight Compression)
Большинство методов, относящихся к легкому сжатию, основаны на словарном кодировании, когда длинные значения преобразуются в более короткие. На практике каждое уникальное значение столбца добавляется в словарь, и каждое появление этого значения заменяется его позицией в словаре (см. Рис.1).
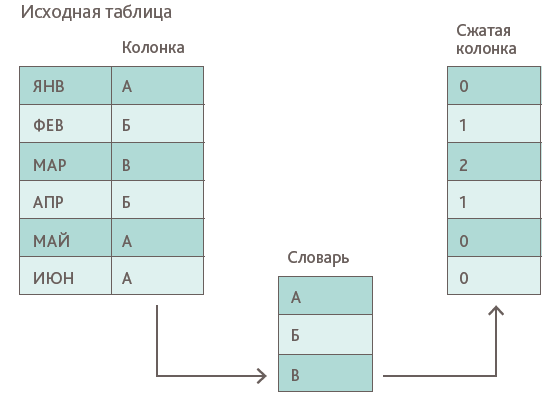
Рис.1. Словарное кодирование
Чтобы сократить последовательность словарных позиций, применяются различные методы словарного кодирования, описанные ниже.
Подавление одинаковых значений (Common Value Suppression)
Во многих сценариях при работе с реальными данными есть столбцы базы данных, содержащие небольшое количество ненулевых значений. В этих случаях столбец хранит повторяющиеся значения. Методы подавления одинаковых значений позволяют избавиться от такой избыточности. Например, префикс кодирования заменяет последовательные одинаковые значения в начале столбца путем хранения количества повторений. При кодировании редких значений (sparse-coding) достигается хорошее сжатие, при условии что много уникальных значений рассредоточено по всему столбцу. Тогда исходный столбец превращается в последовательность нулей и единиц. В случае если значения нет, пишется нуль, в остальных случаях — единица. Также появляется столбец с исключительными значениями, в котором содержатся все уникальные значения, отсортированные в том же порядке, в котором они появляются в исходном столбце (Рис.2). В тех случаях когда преобладающее значение равно нулю, используется метод подавления нулей (null suppression), входящий в число методов подавления одинаковых значений.
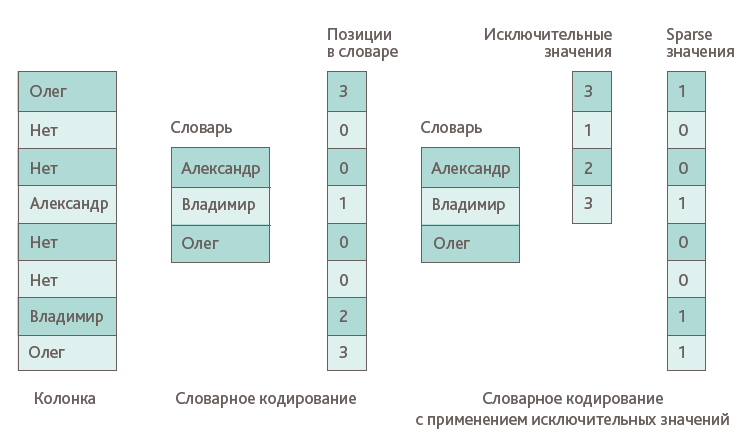
Рис.2. Кодирование редких значений
Кодирование по длинам серий (Run-Length Encoding)
Эта схема кодирования использует количество упоминаний одного и того же значения в столбце. Логически, значение заменяется на количество повторений этого значения подряд. На практике, в базе данных хранится индекс последней строки значения вместо количества повторений (Рис.3). Кодирование по длинам серий (RLE) можно рассматривать как более обобщенное подавление одинаковых значений, которое особенно удобно применять на отсортированных столбцах.
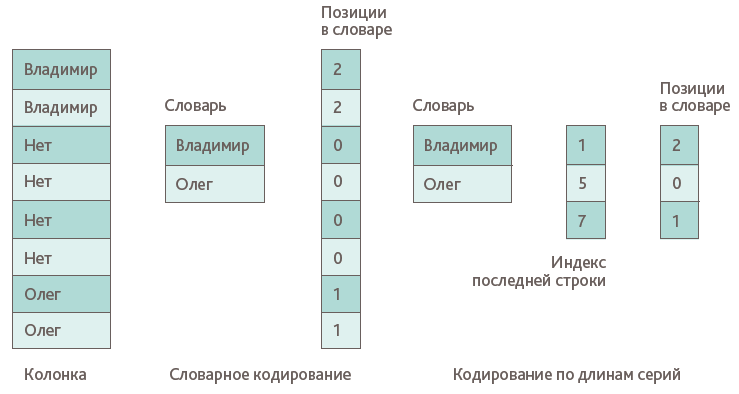
Рис.3. Кодирование по длинам серий
Кластерное кодирование (Cluster Coding)
Кластерное кодирование работает на одинаковых по размеру блоках, содержащих несколько различных значений. Блоки с одним уникальным значением сжимаются при помощи хранения только этого значения в отдельной последовательности. Дополнительный индикатор для каждого блока хранит информацию о том, сжат блок или нет. Индекс соответствующего блока из последовательности может быть получен при помощи целочисленного деления числа строк на размер блока. Выбор правильного блока из последовательности несжатых и явно сохраненных блоков работает по аналогии с извлечением исключительных значений для sparse-кодирования. То есть подсчет всех индикаторов сжатия, содержащих число на единицу больше до данного блока, дает правильное расположение несжатого блока. Этот подсчет также называется рангом блока. Расположение отдельного значения в последовательности сжатого блока рассчитывается по формуле: индекс блока минус ранг блока.
Непрямое кодирование (Indirect Coding)
Подобно кластерному кодированию, непрямое кодирование работает на блоках данных.
Дополнительные словари на уровне блоков позволяют сузить диапазон значений, которые должны быть закодированы, и уменьшают размеры словаря. Доступ к фактическим значениям столбцов осуществляется только косвенно, потому что последовательности целых чисел необходимо сначала обратиться к глобальному словарю, который указывает на содержимое клеток. Как правило, каждый блок может иметь свой собственный словарь, но последующие блоки могут делиться словарями друг с другом. Если блок имеет слишком много различных записей, он также может использовать глобальный словарь напрямую (Рис.4). На практике мы заменяем блок, который нужно сжать, на список, содержащий все уникальные значения, которые появляются в этом блоке, и выступающий в качестве локального словаря. Кроме того, для каждого локально сжатого блока хранится последовательность позиций местного словаря. Для восстановления определенной строки дополнительная структура данных содержит указатель на словарь (локальный или глобальный) и соответствующую позицию в последовательности для каждого блока.
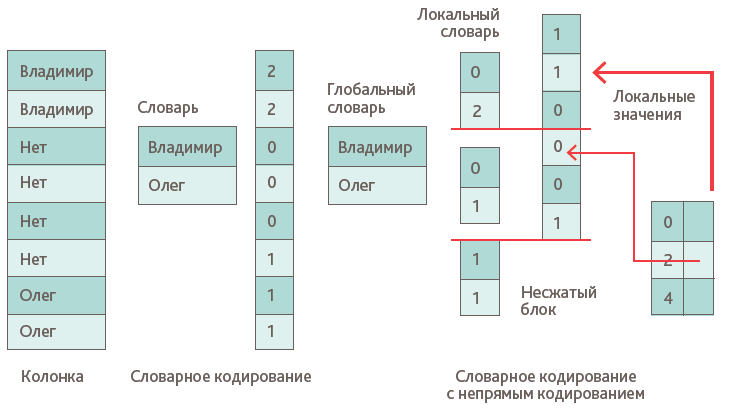
Рис.4. Непрямое кодирование
Кроме того, можно использовать комбинации описанных выше методов. Например, кластерное кодирование может сочетаться с методом подавления нулей с помощью префикса кодирования. Колонка, содержащая много различных значений, будет использовать словарное кодирование без каких-либо модификаций с применением последовательности словарных позиций. Как упоминалось выше, сжатие также может быть применено к сокращенным последовательностям словарных позиций. Однако непрямое кодирование не имеет смысла, если модифицированные значения сохраняются без сжатия, с использованием всей ширины выбранного целочисленного типа данных. Некоторые из наиболее популярных методов уменьшения ширины значения описаны далее.
Битовое сжатие (Bit Compression)
Вместо того чтобы хранить каждое значение с помощью встроенного целочисленного типа данных, битовое сжатие использует только необходимое количество битов для представления значений. То есть значения разбиваются на части фиксированной ширины, причем размер части определяется по величине наибольшего значения, которое нужно закодировать.
Байтовое кодирование (Variable Byte Coding)
По сравнению с битовым сжатием байтовое кодирование использует байты, а не биты как основную единицу для создания частей памяти. Значения разделяются на части по 7 бит, и каждая часть хранится в байте. Оставшийся ведущий бит используется для определения, конец ли это значения или нет. Таким образом, каждое значение может занимать разное количество
Если хотите прочитать статью полностью и оставить свои комментарии присоединяйтесь к sapland
ЗарегистрироватьсяУ вас уже есть учетная запись?
Войти
Обсуждения 2
2
Комментарий от
Виталий Глущенко
| 29 августа 2015, 22:42
При использовании любого сжатия падает прямой доступ к данным. Согласен что при поколоночном доступе словарный алгоритм кодирования не сильно замедляет доступ к данным, тем не менее замедление есть. Поэтому хотелось бы понять как сильно падает производительность? Сугубо моё личное мнение, что для OLTP систем производительность БД - критична. После этого можно будет обсуждать использование сжатия на уровне БД и его методах.
Комментарий от
Олег Точенюк
| 30 августа 2015, 19:39
Виталий Глущенко 29 августа 2015, 22:42
Спасибо, за перечисленные методы сжатия используемые в HANA, но...
При использовании любого сжатия падает прямой доступ к данным. Согласен что при поколоночном доступе словарный алгоритм кодирования не сильно замедляет доступ к данным, тем не менее замедление есть. Поэтому хотелось бы понять как сильно падает производительность? Сугубо моё личное мнение, что для OLTP систем производительность БД - критична. После этого можно будет обсуждать использование сжатия на уровне БД и его методах.