Еще о производительности на хэш-таблицах. Снова тест ни о чем
Заметки старого АБАПника. 007.
Для тех, кому это еще не надоело, продолжаю мусолить тему производительности на хэш-таблицах. Как и раньше исследуется то время, которое нужно в АБАПе для доступа к записи хэш таблицы. Именно это, а не что-то другое. Исследуется экспериментально, на конкретной системе. Сферический конь в вакууме очень интересная конструкция, но практически не наблюдаемая.
В предыдущих обсуждениях высказывалась претензия к конструкции read table gt into... , будто эта конструкция работает существенно медленнее (см. прогу ZQK006A), чем read table gt assigning... (см. прогу ZQK007), продемонстрируем, что в данном случае эти ожидания не оправданы. Вообще-то преимущества read table ... assigning перед read table ... into вещь достойная отдельных исследований, и этим мы предполагаем заняться в дальнейшем.
На других системах, другом железе, в другое время при другом расположении звезд ;-) и другой загрузке системы результаты, разумеется, могут быть другие.
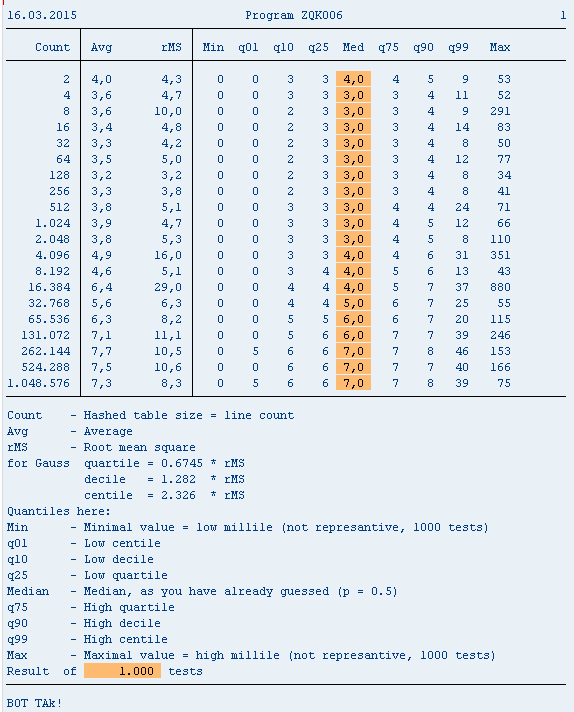
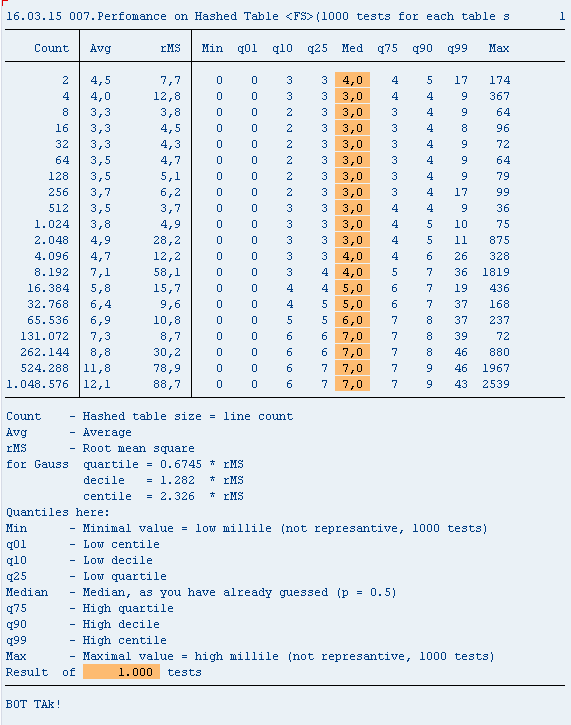
На этот раз попалась система с большей дисперсией времен доступа, поэтому пришлось изменить тип переменных, связанных с вычислением дисперсии и СКО.
* 006A.Perfomance on Hashed Table (1000 tests for each table size)
REPORT ZQK006A.
selection-screen comment /1(80) t_worn.
selection-screen begin of line.
selection-screen comment 1(24) t_power.
parameters p_power type i default 8.
selection-screen end of line.
data
: gp_rpt type i value 1000 " test number
, begin of gs " hashed table line
, nnn type n length 12
, end of gs
, gt like hashed table of gs with unique key nnn
, begin of gs_stat " statistics line
, no type int2
, cnt type int4
, rls type standard table of i " realisation table
, end of gs_stat
, gt_stat like standard table of gs_stat with key no
, gp_cnt type int4 " hashed table size
, gp_trg like gs-nnn " line to be found
, a type i, b type i, t type i
, list_header type string
.
start-of-selection.
do gp_rpt times. " 1000 tests
do p_power times. " Each test
gp_cnt = 2 ** sy-index.
gp_trg = gp_cnt - 1.
free gt.
do gp_cnt times.
add 1 to gs-nnn.
insert gs into table gt.
enddo.
read table gt into gs with table key nnn = gp_trg.
read table gt into gs with table key nnn = 1.
get run time field a.
read table gt into gs with table key nnn = gp_trg.
get run time field b.
t = b - a. " Result
perform result_collection.
enddo. " End of test
enddo. " End of 1000 tests
perform result_processing.
uline.
write " Legend
: / 'Count - Hashed table size = line count'
, / 'Avg - Average'
, / 'rMS - Root mean square '
, / 'for Gauss quartile = 0.6745 * rMS'
, / ' decile = 1.282 * rMS'
, / ' centile = 2.326 * rMS'
, / 'Quantiles here:'
, / 'Min - Minimal value = low millile (not represantive, 1000 tests)'
, / 'q01 - Low centile'
, / 'q10 - Low decile'
, / 'q25 - Low quartile'
, / 'Median - Median, as you have already guessed (p = 0.5)'
, / 'q75 - High quartile'
, / 'q90 - High decile'
, / 'q99 - High centile'
, / 'Max - Maximal value = high millile (not represantive, 1000 tests)'
, / 'Result of', gp_rpt color col_group, 'tests'
, / sy-uline, / 'BOT TAk!'.
load-of-program. " Trifle
t_worn = icon_message_warning &&
'For big power please use background processing. Try 20 or more'.
t_power = 'Table size (Power of 2)'.
top-of-page. " One more trifle
concatenate
` Count | Avg rMS `
`| Min q01 q10 q25 Med q75 q90 q99 Max`
into list_header.
write list_header.
uline.
form result_collection.
clear gs_stat. " Result collecting begin
read table gt_stat into gs_stat index sy-index.
if sy-subrc = 0.
gs_stat-no = sy-index.
gs_stat-cnt = gp_cnt.
append t to gs_stat-rls.
modify gt_stat from gs_stat index gs_stat-no.
else.
gs_stat-no = sy-index.
gs_stat-cnt = gp_cnt.
append t to gs_stat-rls.
append gs_stat to gt_stat.
endif. " Result collecting end
endform.
form result_processing.
data
: rls like line of gs_stat-rls, res type f, rrr type f
, cnt type f value 1000
, disp type p length 6 decimals 1
, avg type p length 2 decimals 1
, rms like disp
, sm1 type f, sm2 type f " initial moments
, infq type int2, supq type int2 " low and high quartiles
, infd type int2, supd type int2 " low and high deciles
, infc type int2, supc type int2 " low and high centiles
, min type int2, max type int2 " minimal and maximal
, med like avg " median
.
loop at gt_stat into gs_stat. " Results
* moments, average, dispersion, rMS
loop at gs_stat-rls into rls.
rrr = res = rls.
sm1 = sm1 + rrr.
rrr = rrr * rls.
sm2 = sm2 + rrr.
rrr = rrr * rls.
endloop.
sm1 = sm1 / cnt.
sm2 = sm2 / cnt.
avg = sm1.
disp = sm2 - sm1.
rms = sqrt( disp ) * ( cnt - 1 ) / cnt.
* nonparametric statistics
sort gs_stat-rls.
read table gs_stat-rls into infq index 500.
read table gs_stat-rls into supq index 501.
med = ( infq + supq ) / 2.
read table gs_stat-rls into infq index 250.
read table gs_stat-rls into supq index 750.
read table gs_stat-rls into infd index 100.
read table gs_stat-rls into supd index 900.
read table gs_stat-rls into infc index 10.
read table gs_stat-rls into supc index 990.
read table gs_stat-rls into min index 1.
Если хотите прочитать статью полностью и оставить свои комментарии присоединяйтесь к sapland
ЗарегистрироватьсяУ вас уже есть учетная запись?
Войти
Обсуждения 2
2
Комментарий от
Олег Точенюк
| 22 апреля 2015, 17:38
read table ... assigning перед read table ... into вещь достойная отдельных исследований
===
А что там исследовать то? Меня конечно в компилятор не пустит никто, но исходя из бытовой логики, там особо исследовать нечего.
read table ... into -> тут идет копирование выбранной записи в рабочую область или заголовок таблицы. Соответственно чем больше запись, чем больше количество полей для копирования, тем это идет дольше.
read table ... assigning -> тут идет предоставление ссылки на запись, т.е. по факту идет создание pointer-а, в качестве доказательства, запись полученную таким образом, можно менять напрямую без последующего MODIFY, т.е. никакого копирования не происходит, идет прямая работа по ссылке на запись.
Из примера, если берем одно поле из таблицы с 20 полями, то разница между методами доступа будет не существенной, а если например таблица типа MSEG и считываем всю запись, то разница уже будет в разы.
PS: Так как при read table ... assigning, получаем по факту ссылку, то была как-то проблема, что человек случайно затирал значение во внутренней таблице. Соответственно MODIFY нет, а данные где-то, как-то и почему-то меняются. Короче пришлось немножко устать, пока нашел эти чужие грабли.
Комментарий от
Денис Озорнов
| 23 апреля 2015, 11:33
2) В этих условиях да,замер INTO vs ASSIGNING показывает собственно то, что видно на картинке. Но, если, к примеру, структуру вашей тестовой таблицы расширить таким образом, что бы длина строки в байтах была примерно больше 1000, результат будет совсем другим