Развитие в экосистеме SAP
Обучение и развитие проектных команд
Станьте участником SAPLAND и получите доступ к самым интересным публикациям SAPPRO
ЗарегистрироватьсяОбучение и развитие проектных команд
Станьте участником SAPLAND и получите доступ к самым интересным публикациям SAPPRO
ЗарегистрироватьсяРазвитие в экосистеме SAP


Занятное замечание: "если я ничего не путаю, то наиболее заметно скорость поиска по хэш табле зависит от собственно длины ключа таблы"
Вы представляете что такое хеш доступ и как он реализуется при построении индекса? Вообще-то скорость доступа зависит не от длинны ключа (ну если мы не ассемблерный код хеш-функции анализируем и такты процессора с внутренними стеками да длину команд высчитываем), а от качества используемого алгоритма - хеш функции. Чем больше коллизий у алгоритма расчета тем медленнее поиск, так как выполняются различные дополнительные методы обхода коллизий и т.д.
PS: Не я понимаю что простое сложение байт строки в 10 символов и строки в 20 выполняется дольше, но мы то про базы данных, а не про что быстрее посчитается на уровне процессора и памяти.

Ну вы их читали, но по факту так ничего в примеры кроме вот этого вот: "являются скорее уж вредными советами" не привели, поэтому беседа как бы ни о чем. Хотя я предложил вам ранее это сделать на конкретных примерах, где по вашему или совет не тот или граната не той системы.
По повожу технического редактора, ну я писал, Александры Дублин и Яков Михалыч Басок редактировали, Василий Ковальский вроде как рецензировал, но если для вас это ни о чем не говорит, то фиг с ним, оригинал тоже подойдет, хотя именно это издание я не читал. Но если вы думаете что мне было нечего делать, просто пересказать своими словами приведенную вами ссылку, то я тоже не возражаю.
PS: По поводу статей, именно статей тут по абапу их вообще-то мало (кажется 2), вы наверное имеете в виду авторские колонки/блоги. Их конечно же кроме автора вряд ли кто редактирует. Кстати, сделайте свою колонки, а мы почитаем...
Занятное замечание: "если я ничего не путаю, то наиболее заметно скорость поиска по хэш табле зависит от собственно длины ключа таблы"
Вы представляете что такое хеш доступ и как он реализуется при построении индекса? Вообще-то скорость доступа зависит не от длинны ключа (ну если мы не ассемблерный код хеш-функции анализируем и такты процессора с внутренними стеками да длину команд высчитываем), а от качества используемого алгоритма - хеш функции. Чем больше коллизий у алгоритма расчета тем медленнее поиск, так как выполняются различные дополнительные методы обхода коллизий и т.д.
PS: Не я понимаю что простое сложение байт строки в 10 символов и строки в 20 выполняется дольше, но мы то про базы данных, а не про что быстрее посчитается на уровне процессора и памяти.

Ну вы их читали, но по факту так ничего в примеры кроме вот этого вот: "являются скорее уж вредными советами" не привели, поэтому беседа как бы ни о чем. Хотя я предложил вам ранее это сделать на конкретных примерах, где по вашему или совет не тот или граната не той системы.
По повожу технического редактора, ну я писал, Александры Дублин и Яков Михалыч Басок редактировали, Василий Ковальский вроде как рецензировал, но если для вас это ни о чем не говорит, то фиг с ним, оригинал тоже подойдет, хотя именно это издание я не читал. Но если вы думаете что мне было нечего делать, просто пересказать своими словами приведенную вами ссылку, то я тоже не возражаю.
PS: По поводу статей, именно статей тут по абапу их вообще-то мало (кажется 2), вы наверное имеете в виду авторские колонки/блоги. Их конечно же кроме автора вряд ли кто редактирует. Кстати, сделайте свою колонки, а мы почитаем...
На мой не скромный взгляд: тест по хэшу ни о чем.
1) скорость измерения для хэш-таблы не коррелирует линейно с числом строк в таблице
2) речь идет о микросекундах, т.е. скорее всего это погрешности связанные с накладными расходами на обслуживание работы с таблой собственно, а не на поиск.
3) для чистоты замеров стоит исключить перекладывание найденных данных, использовав вместо INTO конструкцию TRANSPORTING NO FIELDS
4) если я ничего не путаю, то наиболее заметно скорость поиска по хэш табле зависит от собственно длины ключа таблы.
ЗЫ: Непонятно про рекламируемую книгу: зачем она, если есть первоисточники
sap-press.com/abap-performance-tuning_2092
Вы уж простите, я книгу Точенюка не читал. Но я читал его заметки по производительности с сайта sapforum.biz. Могу сказать, что там были моменты, которые, на мой взгляд, являются скорее уж вредными советами. Т.е. модель "дешево и сердито" конечно хороша, но не стоит забывать про "кроилово ведет к попадалову".
Изданная книга это конечно хорошо, но был ли у нее тех.редактор? На примере статей этого ресурса по ABAP, можно сказать, что они не подвергаются рецензированию и редактуре (да какая редактура, если даже орфографические и синтаксические ошибки в статьях не вычищены?)
печально то, что в СНГ только 2 нормальные книги на русском: Виталия Поцелуева и Олега Точенюка.
далеко нам уже до индусов и остальных - те книги пачками выпускают.
1) очень печально, если программер не может читать на английском хотя бы тех.литературу
2) - папа, зачем ты пьешь водку из горла? Возьми стакан!
- Сынок, папе не нужны посредники!
4) книга на русском. и она дешевле :)
На мой не скромный взгляд: тест по хэшу ни о чем.
1) скорость измерения для хэш-таблы не коррелирует линейно с числом строк в таблице
2) речь идет о микросекундах, т.е. скорее всего это погрешности связанные с накладными расходами на обслуживание работы с таблой собственно, а не на поиск.
3) для чистоты замеров стоит исключить перекладывание найденных данных, использовав вместо INTO конструкцию TRANSPORTING NO FIELDS
4) если я ничего не путаю, то наиболее заметно скорость поиска по хэш табле зависит от собственно длины ключа таблы.
ЗЫ: Непонятно про рекламируемую книгу: зачем она, если есть первоисточники
sap-press.com/abap-performance-tuning_2092

В этой статье сравнивается подход к построению отчётности в BW на «классических» БД. Но на текущий момент есть BW on HANA. Возможна репликация непосредственно в DSO. И построение отчётности на данных приближенных к реальному времени в BW. На рис. 1 представлена модель использования BW, но в «классическом» виде сверху обычно строятся ещё кубы и агрегаты. Только построения дополнительных индексов в DSO будет недостаточно для производительной отчётности.
Кроме этого, хочется отметить,что HANA Live разворачивается из пакета и при импорте активируются все модели. Если исходных таблиц в физической схеме нет, то активация моделей падает. А так как большинство моделей зависят друг от друга, то это также влияет и на зависимые модели. В данном случае выручает массовая активация объектов.
Мэппинг физической схемы и схемы авторизации, которая создаётся при установке HANA Live влияет на доступ ко всем таблицам моделей, включая пересчёт валют. И единиц измерений. VDM (Виртуальные модели данных) которые предлагает HANA Live можно использовать не только в любых средствах отчётности, но также и писать SELECT-ы напрямую из ABAP-а, так как это самые обыкновенные ракурсы в HANA.
В плане расширения и дополнения также есть некоторые ограничения, так как для собственных Z-моделей, которые были скопированы в свои пакеты нельзя автоматически добавить в уже имеющуюся иерархию, так как сама иерархия ведётся в отдельной таблице. То есть HANA Live Browser или по-другому HANA Live Explorer не позволяет их вести, они все (модели) будут в разделе «не присвоенные».
Виктор, спасибо за Ваши публикации.
У меня вопрос относительно "инициация процедур создания новой записи ЕО при приемке на склад МТО вновь поступающего оборудования", рассматривали ли Вы в теории, возможность использования функциональности "серийные номера" для решения данной задачи, либо использовали СН на практике? Если отклонили СН, то по каким причинам?
Спасибо за ответ.


В статье автор использует достаточно длинные пути к настроечным транзакциям.
Удобно использовать такие транзакции (можно создать папку в фаворитах):
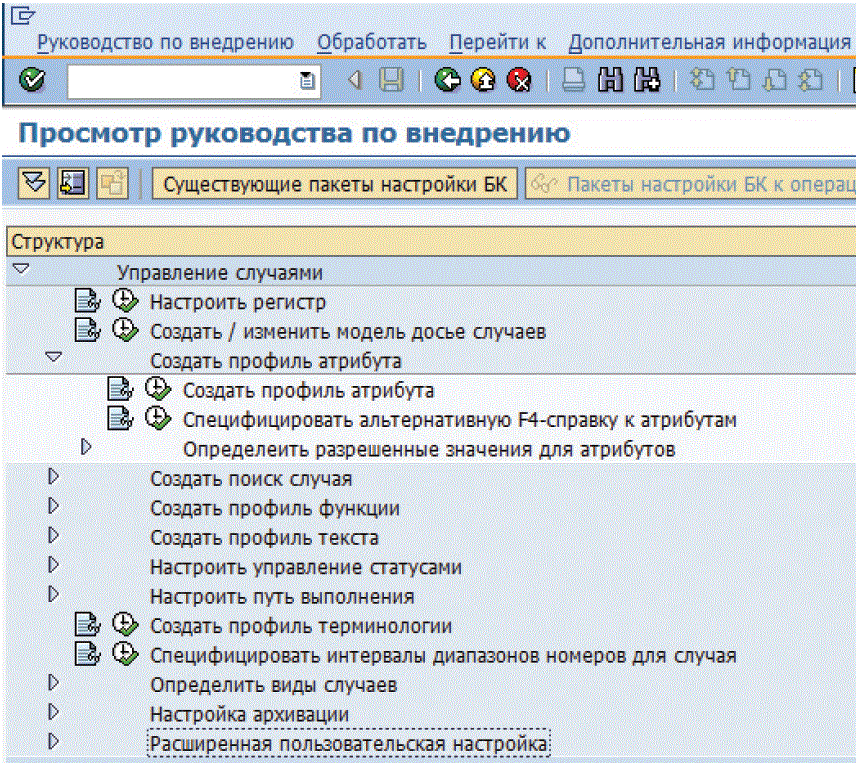
Рис. 8. Вид меню настройки управления случаями при запуске транзакции SCASE_CUSTOMIZING

















Комментарий от
Олег Точенюк
| 22 ноября 2014, 16:27
Денис Озорнов 21 ноября 2014, 09:49
Собственно вот цитата из курса BC402 (версия 2006 Q2, страница 200) про то, какой алгоритм используется для хэш-таблиц.
Access to a hashed table is implemented using a hash algorithm. Simplified, this
means that the data records are distributed randomly but evenly over a particular
memory area. The addresses are saved in a separate table, the hashed table. To
do this, a hash function uses the key data to calculate an address where the hashed
table entry can be found.
The function is not injective, that is, there can be two data records stored at a single
address. This is implemented internally as a chained list. Therefore, the system may
have to perform a sequential search within this type of area. However, the chained list
can only contain a maximum of two entries. If the same hash table address results
for a third new key, the system uses a changed hash function and rebuilds the entire
management area. The graphic illustrates the simplest case, in which only one record
is stored at each address.