Развитие в экосистеме SAP
Обучение и развитие проектных команд
Станьте участником SAPLAND и получите доступ к самым интересным публикациям SAPPRO
ЗарегистрироватьсяОбучение и развитие проектных команд
Станьте участником SAPLAND и получите доступ к самым интересным публикациям SAPPRO
ЗарегистрироватьсяРазвитие в экосистеме SAP


Транзакция Uase16n. В окне ввода транзакции введите дополнительный код открытия режима редактирования &sap_edit



Ну так по факту все вылилось в определение доступа к памяти конкретной тестируемой системы, а это не время доступа к хеш-таблице. Кстати можно запустить по такому же алгоритму, проверку времени доступа по индексу к стандартной таблице. Думаю время доступа будет тоже замедлятся с увеличением размеров этой таблицы, при произвольном чтении записей.
>Ну так по факту все вылилось в определение доступа к памяти конкретной тестируемой системы,
Истина всегда конкретна (с)Г.В.Ф. Гегель
>а это не время доступа к хеш-таблице.
Напротив. Это именно оно. Абаперу АБАП дан только в конкретных системах
в конкретное время при конкретной загрузке этих систем прочими задачами
Все остальное из-под АБАПа недоступно
>Кстати можно запустить по такому же алгоритму, проверку времени доступа по индексу к стандартной таблице.
Непременно.
>Думаю время доступа будет тоже замедлятся с увеличением размеров этой таблицы, при произвольном чтении записей
Бинго! Именно так оно о и есть и никак не иначе! То, что индексный доступ к внутренним таблицам не зависит от размера, это тоже один из мифов.

«Вообще-то похоже измерения хэш-функции, плавно перетекли в измерения скорости доступа к данным находящимся в памяти системы.»
Это не к Злоберманну. Злоберманн писал только о времени доступа к хеш таблице. В обсуждении реализации алгоритма хеширования Злоберманн не участвует,
ибо из-под АБАПа это не доступно, а мои записки касаются именно АБАПа.
Вообще-то похоже измерения хэш-функции, плавно перетекли в измерения скорости доступа к данным находящимся в памяти системы. И тут уже вариантов просто вагон, начиная от типа операционной системы и заканчивая вариантами используемого менеджера памяти для никсовых систем (а их там в отличии от винды можно менять). По факту, кто сказал что таблица в памяти, да она может быть где угодно и чем больше таблица, тем вероятнее всего, что ее части находятся где-то вплоть до диска, что и вызывает аномальную задержку при чтении такого участка. Далее разбросы в 2-4 милисекунды, опять же ну попало в кеш процессора частичная команда, ну оно и сбросило весь кеш и загрузило его по новой от этой неполной команды и дальше что влезло (раньше влезало по 8 байт), вот вам и такты на перегруз кеша (кстати в хане это одно из достоинств, что микрокод выровнен по процессору и таких вот перегрузок не бывает), в общем смысла в этих милисекундах, если честно особо не вижу, кроме того что если таблица большая, то доступ, а фактически получение любой произвольной записи будет дольше, ну это как бы и так ясно должно было быть по причине описанной выше. Кстати доступ по индексу к любой большой таблице теоретически тоже должен возрастать при увеличении размера таблицы, хотя там вроде как считается все быстро.
Что касается самой хеш-функции, то вряд ли нам кто даст посмотреть на ее реализацию и соответственно оценить почему и как.
PS: По поводу синхронно/асинхронных обновлений я пока, к сожалению, системы где это можно смоделировать не имею, но про это помню :-), не смотрю на то что посты там потерли.
«Вообще-то похоже измерения хэш-функции, плавно перетекли в измерения скорости доступа к данным находящимся в памяти системы.»
Это не к Злоберманну. Злоберманн писал только о времени доступа к хеш таблице. В обсуждении реализации алгоритма хеширования Злоберманн не участвует,
ибо из-под АБАПа это не доступно, а мои записки касаются именно АБАПа.

Интересная вещь: "Не смотря на ограничение модели на основе бухгалтерских проводок перечнем хозяйственных операций в бухгалтерском учете", ну я то думал, что перечень хозяйственных операций в компании должен покрывать, как мне казалось, всю сферу деятельности компании, соответственно бюджет включает в этом случае, так же в себя все финансовые направления деятельности компании. Но тут оказывается это не так, бюджет, я так понял может быть никак не связан с хозяйственной деятельностью компании? Не ну скажем так, если директор что-то из финансовых потоков заворачивает лично себе на карман, то конечно да, статью бюджета в BW мы такую сделать можем (наша система что хотим то и вертим), а вот хозяйственную операцию типа кредит каких-то денеХ, дебет карман директора, это вряд ли (первая же проверка спросит а что это). Ну или я кажется с группой товарищей не понял всей глубины данной фразы.
PS: Хотя я там по тексту, кажется вообще ничего местами не понял... а объяснить мне почему-то это, окружающие финансисты и экономисты тоже не могут.

Поспешность хороша при ловле блох.
А вот подождать некоторое время придется. Злоберманн стремится к доказательности и старается не допускать голословных утверждений. Тем более, что читатели у меня замечательные, внимательные. Но вот работать тоже иногда приходится.
С одной стороны весьма отрадно, что тема Вас заинтересовала, но кроме того замечаю: переход на личности, фаллометрия, попытка троллинга.
1) "Можете называть Злоберманна трусливым койотом". См. Выше.
2) "в части раскидывания данных по квартилям, как мне кажется, это опять "ни о чем"."
Не могу согласиться. Квантили - общепринятый инструмент непараметрических статистик.
"По моему скромному мнению, тут бы скорее подошла гистограмма "сколько в штуках чтений пришлось на тот или иной участок стат.распределения". Такие данные были бы гораздо показательнее."
Намекаете, что могут быть дополнительные моды? Я их не жду, но этот вопрос я не исследовал. Займетесь?
Что до меня, то на данном этапе меня интересуют не особенности этого распределения. Меня интересует факт зависимости времени поиска по хэш-таблице от ее размера. Каковой факт и был продемонстрирован.
3) "повторюсь, как и в предыдущем обсуждении: есть аномальные значения, явно выбивающиеся из линейной корреляции"
Так она все же, есть линейная корреляция? Я не считал, но Вам верю на слово.
"предположу, что это вызвано нагрузкой на железо апп.сервера, не связанной с работой программы),"
Ну да. Производительность хэш таблицы таки зависит от размера. Именно таблицы. Производительность собственно алгоритма хеширования из-под АБАПа померить сложновато. Буду рад, если Вы найдете способ и сообщите.
"а так же - речь идет о микросекундех, т.е. отклонения по абсолютному значению времени не значительны, что и видно из вашего теста. (опять же, вспоминается хелп из версии 4.0, в котором обычно для каждой операции указывался разброс возможного времени выполнения в микросекундах)"
А как Вам 2 миллискенды? Точнее 1944 микросекунд.
1) "Можете называть Злоберманна трусливым койотом". См. Выше.
2) "в части раскидывания данных по квартилям, как мне кажется, это опять "ни о чем"."
Не могу согласиться. Квантили - общепринятый инструмент непараметрических статистик.
"По моему скромному мнению, тут бы скорее подошла гистограмма "сколько в штуках чтений пришлось на тот или иной участок стат.распределения". Такие данные были бы гораздо показательнее."
Намекаете, что могут быть дополнительные моды? Я их не жду, но этот вопрос я не исследовал. Займетесь?
Что до меня, то на данном этапе меня интересуют не особенности этого распределения. Меня интересует факт зависимости времени поиска по хэш-таблице от ее размера. Каковой факт и был продемонстрирован.
3) "повторюсь, как и в предыдущем обсуждении: есть аномальные значения, явно выбивающиеся из линейной корреляции"
Так она все же, есть линейная корреляция? Я не считал, но Вам верю на слово.
"предположу, что это вызвано нагрузкой на железо апп.сервера, не связанной с работой программы),"
Ну да. Производительность хэш таблицы таки зависит от размера. Именно таблицы. Производительность собственно алгоритма хеширования из-под АБАПа померить сложновато. Буду рад, если Вы найдете способ и сообщите.
"а так же - речь идет о микросекундех, т.е. отклонения по абсолютному значению времени не значительны, что и видно из вашего теста. (опять же, вспоминается хелп из версии 4.0, в котором обычно для каждой операции указывался разброс возможного времени выполнения в микросекундах)"
А как Вам 2 миллискенды? Точнее 1944 микросекунд.
В комментарии к статье призывается дух наполеона(зачеркнуто) того, кто любит себя называть Злоберманном. Или уважаемый (опять же это его самоназвание) "старый абапник" считает ниже своего достоинства вступать в полемику со спецами, с которыми он спешит поделится крупицами своего опыта? Нам следует ждать статью с опровержением комментариев опять через 2 месяца? Или все-таки можно надеяться постигнуть свои ошибки чуть ранее?
Согласен, действительно тест ни о чем.
Если бы вы действительно занимались оптимизацией, то вместо
read table gs_stat-rls into infq index 250.
использовали бы
read table gs_stat-rls assigning <fs> index 250.
В этом случае ваши замеры действительно показывали бы время обращения к таблице приближенное к реальности. А так, большая часть всех этих тысяч секунд потрачена на бесполезное копирование данных из таблицы в строку.
PS: ошибку исправьте в слове "полпадают".
1) я солидарен с Влерием. Смысл очистки таблицы и повторного ее заполнения при таком тесте для меня не ясен. Это же не вытаскивание данных из СУБД.
2) в части раскидывания данных по квартилям, как мне кажется, это опять "ни о чем". По моему скромному мнению, тут бы скорее подошла гистограмма "сколько в штуках чтений пришлось на тот или иной участок стат.распределения". Такие данные были бы гораздо показательнее. Но, в принципе, и так видно, что большей частью все значения времени чтения сосредоточенны в левой части распределения.
3) повторюсь, как и в предыдущем обсуждении: есть аномальные значения, явно выбивающиеся из линейной корреляции(имея ввиду, что речь идет о вычислениях, а не о чтении СУБД, предположу, что это вызвано нагрузкой на железо апп.сервера, не связанной с работой программы), а так же - речь идет о микросекундех, т.е. отклонения по абсолютному значению времени не значительны, что и видно из вашего теста. (опять же, вспоминается хелп из версии 4.0, в котором обычно для каждой операции указывался разброс возможного времени выполнения в микросекундах)
Не очень понял след.момент: "Мне представляется важным, чтобы для каждого размера проводилось не по 1000 измерений к одной и той же таблице, но чтобы таблица перестраивалась перед каждым измерением".
Но, насколько мне известно, назначение хэш-таблиц - это чтение по неизменяемым/малоизменяемым таблицам достаточного объема, т.е. когда наполнение таблицы происходит один раз и затем содержимое либо не меняется, либо мало меняется.
Поэтому мне видится, что для целей практического использования тест с 1000 чтениями по одному и тому же содержимому был бы ценней, чем 1 чтения по 1000 содержимым. Или ошибаюсь?
Аннотация к комментарию
Используя предложенные в комментарии к статье пошаговые инструкции, вы сможете сэкономить порядка 80% времени при решении задач массового изменения данных, а также сможете создавать унифицированный интерфейс для работы с изменениями любых типов объектов системы конечным пользователем.
Довольно часто возникает необходимость массового изменения данных в SAP ERP. Например, это данные технических мест или данные карточек ОС. Делать обновление данных в таблицах системы «вручную» категорически запрещено, допустимо только изменение данных с использованием стандартных транзакций системы так, чтобы информация об изменениях осталась в журналах обработки и т.д.
Компания SAP предоставляет программные интерфейсы в виде функций BAPI, которые позволяют выполнять изменения объектов путём написания собственной Z-программы массовой обработки данных. Разработка Z-программы такого рода обычно состоит из следующих шагов:
Если теперь перевести эти соображения на язык программы, то скорее всего самой сложной частью работ будет обработка диалога с пользователем, так как шаг 4, при наличии соответствующих BAPI-функций (в крайнем случае, можно использовать пакетный ввод) занимает в среднем около 20% от всей разработки. Используя предложенные ниже инструкции, вы сможете сэкономить порядка 80% времени при решении задач массового изменения данных, также получите унифицированный интерфейс для работы с изменениями любых объектов системы конечным пользователем.
В системе SAP ERP есть хорошая транзакция для выполнения массового изменения данных – MASS, которая позволяет это выполнять такие операции. Описание работы с транзакцией MASS приведено в комментируемой статье.
Когда у меня появилась задача массового изменения карточек ОС (Основных средств), я попытался использовать транзакцию MASS, но обнаружил, что она не работает с типом объекта «Техническое место». В стандартной системе перечень типов объектов, с которыми работает данная транзакция невелик. Стандартный список объектов транзакции MASS, приведен на рисунке MASS-01.png.
Я задался целью расширить список типов объектов, данных которых можно массово изменять с помощью данной транзакции, объектом «Техническое место». В данной статье описывается методика (пошаговое руководство) такого расширения.

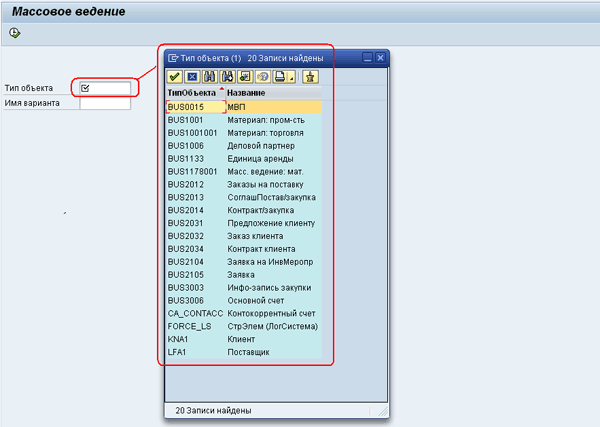
Рис 1. MASS-01.png: Стандартный список объектов транзакции MASS
Нужно задать имя бизнес-объекта для объекта «Техническое место». Имя можно добавить любое. Существующие в системе имена типов объектов, используемых в транзакции MASS, можно увидеть через код поиска в таблицах:
После добавления в эти таблицы «вашего типа объекта» он будет отображаться для выбора в транзакции MASS. Для ввода требуемых данных можно воспользоваться ракурсом ведения, транзакция SM30: MASSFUNC, в которой добавим наш новый тип объекта – «Техническое место».
| Примечание |
| Так как для объектов «Техническое место» в системе есть код бизнес-объекта, то воспользуемся существующим именем. Определить имя бизнес объекта, можно используя таблицу TOJTB – Основные данные репозитария бизнес-объектов. Для этого нужно зайти в просмотр данных таблицы и через код поиска значений к полю NAME можно определить, какие есть бизнес-объекты для технических мест. Как видим, в системе существует 4 типа объекта (см. Рис. 2: MASS-02.png), мы возьмём BUS0010, чтобы было похоже на то, что есть в таблицах транзакции MASS. Еще раз напоминаю, что на самом деле никакой связи транзакции MASS с данными бизнес-объектов нет, поэтому будет ли это имя из таблицы TOJTB или же это будет ваше собственное имя, в принципе все равно, но в целом для поддержания общих принципов наименования объектов, правильно будет использовать имена стандартных бизнес-объектов из таблицы TOJTB. |

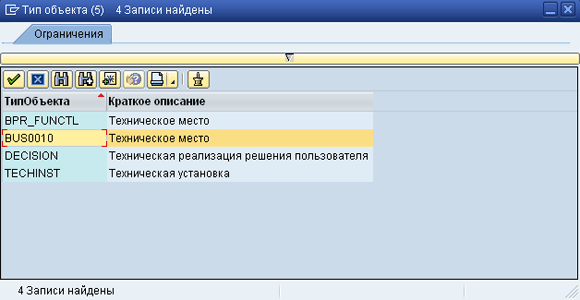
Рис 2. MASS-02.png: Выбор типа объекта
Добавим в ракурсе ведения MASSFUNC, следующие данные, Рис. 3: MASS-03.png.

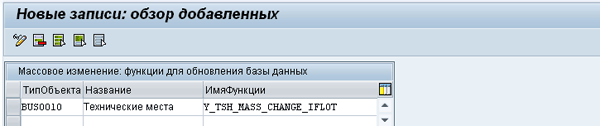
Рис 3. MASS-03.png: Добавление данных в в ракурсе ведения MASSFUNC
Имя объекта берем из таблицы TOJTB, указав в комментарии, что это объект массового изменения для технических мест, далее имя функции: Y_TSH_MASS_CHANGE_IFLOT, этой функции еще не существует, это ваше пользовательское имя функции, которую будет вызывать транзакция MASS, для физического изменения технических мест в базе данных. О реализации функции будет рассказано ниже. Пока просто «придумаем» имя, правила наименования пользовательских объектов разработки стандартные, я назвал функциональный модуль, начиная с буквы Y_. Сохраним данные: система запросит имя транспорта для переноса. Создадим запрос, в который будем записывать, как данные настройки, так и программный код, который создадим позже.
Если теперь зайти в транзакцию MASS, то на первом экране в списке выбора появится наш объект ведения данных для технических мест. Правда пока ничего еще не работает, так что, переходить к ведению данных еще рано, хотя если и перейти, то закладки выбора данных будут пустыми. Как видим, объект уже выбирается и транзакция MASS, что-то уже об этом объекте знает, Рис. 4: MASS-04.png.

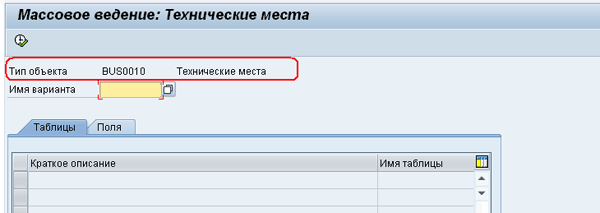
Рис 4. MASS-04.png: транзакция MASS
Теперь добавим имена таблиц и полей, которые можно будет изменять в транзакции MASS. В общем виде можно указать все таблицы, в которых хранятся данные технических места, например, это таблицы IFLOT, ILOA и другие, а затем перечислить все поля этих таблиц. Однако нужно понимать, что фактически система не даст изменить все поля технического места. Если вы зайдёте в транзакцию изменения технических мест IL02, то сможете определить: какие поля можно менять, а какие закрыты от изменений, (например, код технического места и код балансовой единицы, изменить нельзя).
Мы будем добавлять для возможности использования в транзакции MASS таблицу IFLOT и следующие поля этой таблицы:
MAPAR – Номер детали производителя
IWERK – Завод, планирующий ТОРО
EQART – Вид технического объекта
INVNR – Инвентарный номер
GROES – Величина/размер
BRGEW – Вес брутто
GEWEI – Единица измерения веса
ANSDT – Дата покупки
SERGE – Серийный номер изготовителя
Есть несколько вариантов определения возможности изменения данных транзакцией MASS. Первый вариант: перечислить таблицы и поля в «ручном режиме»; второй вариант: указать «использовать все поля», а затем написать специальный функциональный модуль, который удалит из полного списка те поля, которые нельзя изменять; третий вариант: сделать структуру/ракурс, в который включить только поля, разрешенные для изменения. Какой вариант выбрать? Если предполагается разрешить пользователю для изменения 2 – 5 полей из 59, которые есть в таблице IFLOT, тогда, вероятно, проще выбрать вариант 1 или вариант 3. Если - 50 полей из 59, то вариант 2 будет оптимальным, т.е. даем изменять все поля, и пишем модуль, который исключит из этого списка 9 полей, запрещенных к изменению.
Имена таблиц требуется задать в таблице MASSTAB, а поля, если нужно, в таблице MASSFLDLST. Если выбран вариант ведения 2, то для данной таблицы также есть ракурс ведения. Какие внести данные, можно легко определить: в таблице MASSFLDLST всего три поля. Для нашего примера предпочтителен вариант 3, т.е. необходимо создать ракурс ведения таблицы IFLOT, в который включить только разрешённые к изменениям поля, перечисленные выше. Как было сказано, для задания значений у таблиц существуют ракурсы ведения, с такими же точно именами, как и у таблиц.
Итак, сначала идем в создание ракурса ведения для таблицы IFLOT, транзакция SE11 - создать ракурс. Создаём ракурс YTSH_IFLOTSTRUCT – Ведение технических мест для транзакции MASS - ракурс только для чтения таблицы IFLOT, Рис. 5: MASS-05.png. Кроме полей, предназначенных для изменения в транзакции MASS, в ракурс требуется включить также ключевые поля таблицы IFLOT.

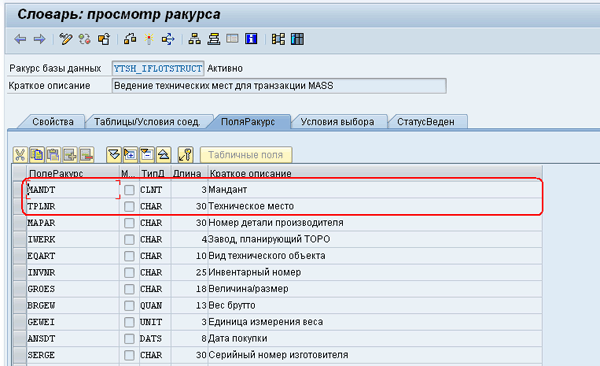
Рис 5. MASS-05.png: ракурс YTSH_IFLOTSTRUCT
Теперь укажем этот ракурс в таблице MASSTAB через транзакцию ведения SM30. Тип объекта укажем BUS0010, который мы выбрали ранее. В поле имя таблицы зададим имя ракурса YTSH_IFLOTSTRUCT. Далее в поле «Число» укажем, например, значение 10. Данное поле служит для упорядочивания списка таблиц: если, например, таблиц/сегментов для обновления больше одной (что в нашем примере неактуально, так как у нас всего одна таблица). В поле «Таб БД» укажем имя таблицы базы данных, из которой фактически будет идти выборка. Для чего требуется указать имя таблицы в колонке «Таб. БД»? Суть заключается в следующем: в поле «Таблица» задаём имя структуры, содержащей только поля, разрешенные для изменения, которые и предложит транзакция MASS для выбора пользователю.
Однако часто ситуация заключается в том, что, например, мы разрешаем изменять поле «Серийный номер», при этом критерием выбора записей для обработки, в которых будет изменяться, является значение поля «Вид технического места», при этом не должно быть разрешено изменять это поле. Мы задали имя основной таблицы базы данных - IFLOT, что служит для транзакции MASS командой предложить пользователю все поля этой таблицы на селекционном экране выбора записей, которые предполагается изменить. Если выборка данных должна выполняться как-то особенно, то в поле «ФМ выбора», нужно задать имя функционального модуля выполняющего выборку данных. В общем случае достаточно стандартных функций выбора данных. И последнее, поле «Без нов. сегментов», в котором поставлена галка, представляет чек-бокса определяющий то, что транзакция MASS позволяет не только изменять данные, но и массово создавать новые данные. В рассматриваемом примере создание новых записей технических мест рассматриваться не будет, по этому мы отключили закладку создания новых технических мест (так как не будем использовать эту функциональность). Пример создания записи, Рис. 6: MASS-06.png.

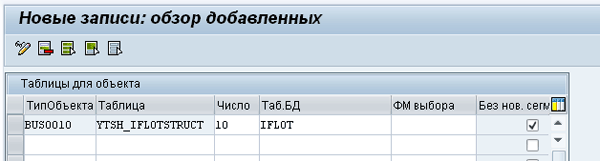
Рис 6. MASS-06.png: Пример создания записи
Теперь, если перейти в транзакцию MASS, то картина будет более интересной, Рис. 7, MASS-07.png. Как видим, теперь транзакция MASS знает нашу структуру и поля, которые мы хотим разрешить изменять. Кроме этого программа уже умеет искать поля, используя кнопки поиска 
 (справа от списка полей). Поиск может идти как по названию, так и техническому имени поля. Конечно, в данном случае, это не очень важно, так как набор полей для изменения ограничен, однако, если полей в списке много, то такая возможность не является лишней.
(справа от списка полей). Поиск может идти как по названию, так и техническому имени поля. Конечно, в данном случае, это не очень важно, так как набор полей для изменения ограничен, однако, если полей в списке много, то такая возможность не является лишней.

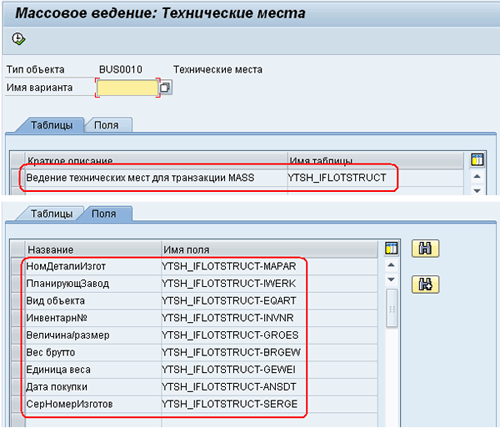
Рис 7. MASS-07.png: Транзакция MASS
Фактически, в данный момент мы должны выбрать нашу таблицу, она одна в списке и выбрать поля которые хотим изменить: можно выбрать как весь набор полей, так и отдельные поля, например, пусть это будет поле «Планирующий завод» и «Дата покупки». Для выбора выделим эти поля в таблице, нажав кнопки выбора слева от каждого поля, после чего можно нажать кнопку выполнить вверху экрана, Рис. 8: MASS-08.png.

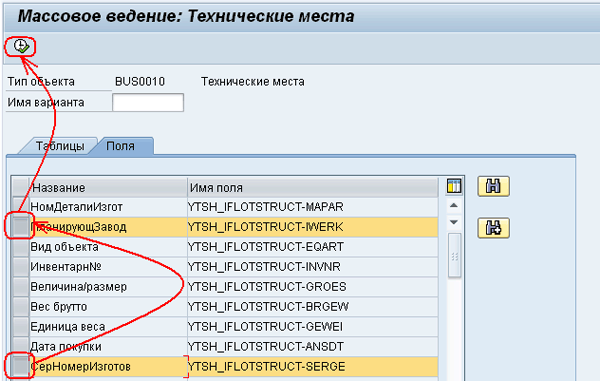
Рис 8. MASS-08.png: транзакция MASS, выбор полей для изменения
Транзакция перейдет к экрану выбора технических мест, которые мы хотим изменить. Фактически, это уже описание работы с транзакцией MASS. По умолчанию, выбор предполагается по ключевым полям, в данном случае – это поле кодов технических мест. Однако транзакция MASS разрешает сделать выбор данных по любым полям, которые есть в таблице IFLOT, так как мы задали именно эту таблицу в настройке выше. Добавим на экран выбора поля: «планирующий завод» и «тип технического места», Рис. 9: MASS-09.png.
Затем укажем – выбрать все технические места, у которых не задан планирующий завод, после чего нажмём F8 – выполнить выбор данных. Система сообщит, сколько записей попадают под указанные критерии и предложит: или перейти к обработке изменений в диалоге, или выполнить фоновое изменение данных, используя создание варианта выполнения. В данный момент мы будем выполнять все операции в диалоговом режиме, поэтому выберем кнопку «Просмотреть все записи». В тестовой системе было выбрано 127 записей без присвоенного планирующего завода.

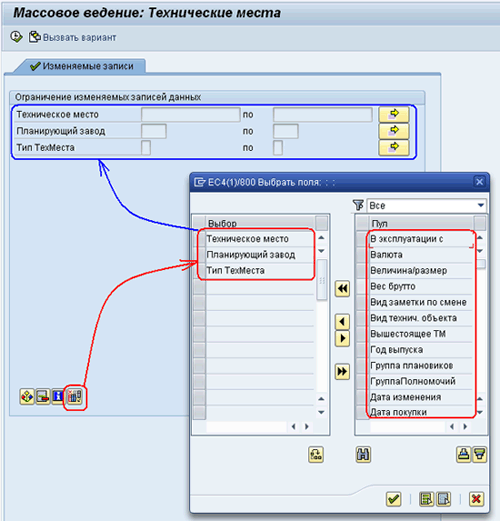
Рис 9. MASS-09.png: транзакция MASS, выбор полей для изменения
Описание работы с транзакцией MASS выходит за рамки данной статьи, поэтому, что и как можно задавать на экране ввода значений определяйте экспериментальным путем или прочитайте статью, на которую была дана ссылка вначале (возможно, что-то найдется в документации SAP). В примере мы задали «установить завод 1000», а для формирования серийного номера изготовителя задали кодировку на языке ABAP, т.е. фактически там идет генерация GUID-а, после чего нажал кнопку 
 – копирования значений в поля и система показала какими значениями, будет выполнено заполнение полей, Рис. 10: MASS-10.png.
– копирования значений в поля и система показала какими значениями, будет выполнено заполнение полей, Рис. 10: MASS-10.png.

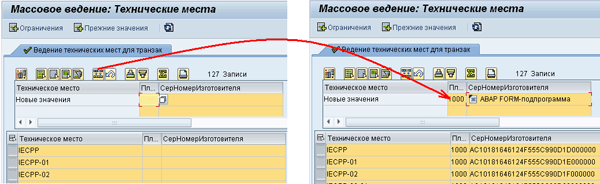
Рис 10. MASS-10.png
Как видим, для поля серийного номера изготовителя были сгенерированы уникальные серийные номера. Пример подпрограммы кодировки для генерации внешних серийных номеров для транзакции MASS следующий (система сама генерируют заголовок подпрограммы):
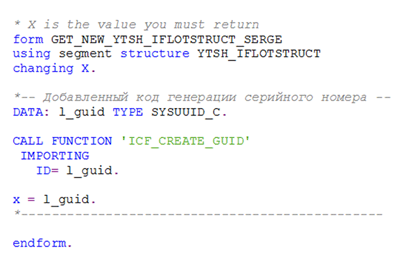

Для обновления данных следует нажать кнопку сохранения результата. Однако пока еще не готова реализация собственно самого функционального модуля Y_TSH_MASS_CHANGE_IFLOT, который выполнит обновление данных на основании заполненных пользователями критериям. Фактически, не более чем за 15-20 минут мы создали диалоговую транзакцию для массового изменения необходимых нам данных с гибким вводом. Реализация, функции изменения данных объекта, будет рассмотрена ниже.
Все сообщения, возникшие в ходе обновления данных, должны быть записаны в журнал обработки данных (далее журнал) и затем транзакция MASS покажет для каждой записи статус обновления или любую другую информацию, которая будет записана в журнал. Поэтому надо настроить наш бизнес-объект на управление журналом. Журнал настраивается с помощью ракурса ведения V_BALSUB – Журнал приложений: ракурс для ведения подобъектов. Для этого через транзакцию SM30 выполним ведение ракурса, появится экран запроса рабочей области, Рис. 11: MASS-11.png.

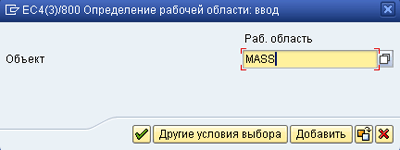
Рис 11. MASS-11.png: транзакция SM30 – экран запроса рабочей области
Имя рабочей области MASS, как и у транзакции ведения данных, поэтому введем код области и перейдем на следующий экран ведения данных, где добавим новую запись, Рис. 12: MASS-12.png (нужно ввести только имя объекта и текст описания).

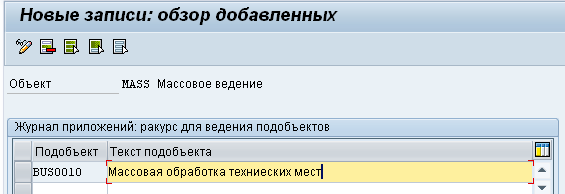
Рис 12. MASS-12.png: ввод имени объекта и текста описания
Сохраним значения в запрос, фактически еще одни шаг по настройке транзакции MASS выполнен.
Эта настройка необязательна, но если необходимо, чтобы массовое ведение выглядело как в стандарте, то её лучше сделать. Назначение настройки заключается в том, что она обеспечивает переход из журнала транзакции MASS в просмотр или изменение обрабатываемых объектов (в нашем примере - технических мест). Если данную настройку не сделать, то журнал обработки будет выглядеть следующим образом, Рис. 13: MASS-13.png.

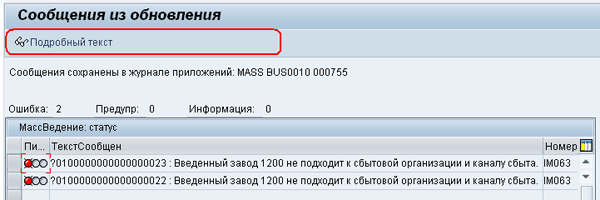
Рис 13. MASS-13.png: вид журнала обработки без настройки
Мы видим на панели инструментов только кнопку просмотра подробного текста к сообщениям об обработке. На рисунке отображён результата попытки присвоить значение поля «завод», равное 1200, для двух объектов. Система не разрешила выполнить такую операцию и сообщила причину.
Перейдём к ведению ракурса MASSAPPEX, в который добавим имена двух функциональных модулей, один для просмотра данных объекта (технического места), а другой для изменения. Как только такие данные будут добавлены, транзакция MASS выведет на панели инструментов две кнопки, для просмотра и изменения объектов из журнала, Рис. 14: MASS-14.png.


Рис 14. MASS-14.png: ведение ракурса MASSAPPEX
В поле CHAR20 имена событий, которые можно выбрать. Имена функциональных модулей, как и в случае с модулем обновления данных, пока только задаем, а их реализация будет описана ниже. Сохраняем данные, если теперь выполнить запуск массового изменения, то в журнале обработки появятся две кнопки, просмотра и изменения обрабатываемых объектов, Рис. 15: MASS-15.png.

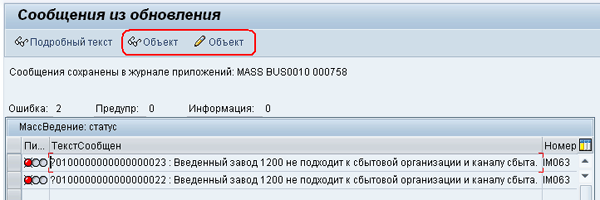
Рис 15. MASS-15.png: вид журнала обработки с настройкой
| Примечание |
| Вы не сможете получить журнал обработки до реализации пункта «Реализация функции обновления данных Y_TSH_MASS_CHANGE_IFLOT», т.е. результаты обработки будут видны только после того, как будут написаны объявленные ранее функциональные модули изменения и просмотра объектов. |
Для возможности запуска транзакции MASS в тестовом режиме необходимо добавить событие «TEST_MODE_KNOWN», так как описано в предыдущем разделе, в ракурс ведения MASSAPPEX в имени функционального модуля необходимо указать *, Рис. 16: MASS-16.png. Данное событие, позволит запускать транзакцию массового изменения с признаком тестового режима. Описание параметров будет сделано ниже.

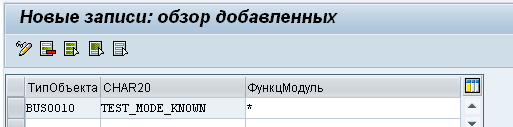
Рис 16. MASS-16.png: настройка тестового запуска
После добавления этого события, если перейти в режим обработки данных транзакции MASS, на экране обновления данных на панели инструментов появится кнопка запуска транзакции в тестовом режиме, Рис. 17: MASS-17.png.

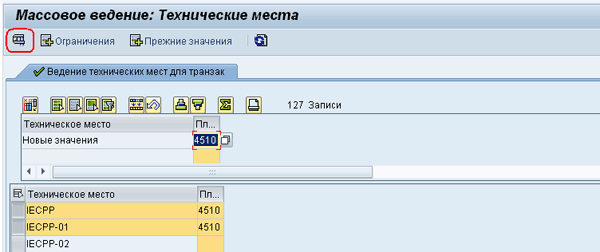
Рис 17. MASS-17.png: режим обработки данных
Если выполнить транзакцию в тестовом режиме, то в журнале появится сообщение, что изменения не сохранены, Рис. 18: MASS-18.png. Необходимо всегда обращать внимание на режим запуска транзакции MASS: тестовый или продуктивный, в функции Y_TSH_MASS_CHANGE_IFLOT, когда будете выполнять ее реализацию.

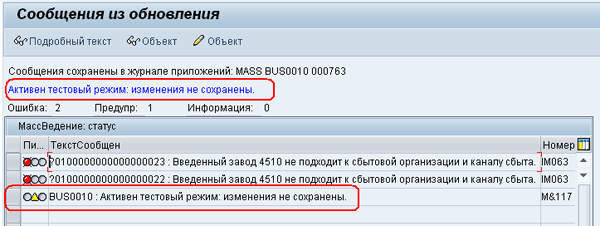
Рис 18. MASS-18.png: выполнение транзакции в тестовом режиме
Для типов объектов «техническое место», начиная с версии системы 4.6, существует BAPI функция, которая позволяет изменять программно данные технического места: BAPI_FUNCLOC_CHANGE. Если до этого места особого знания языка ABAP не требовалось, то реализация данного пункта невозможна без знаний ABAP, так как функция Y_TSH_MASS_CHANGE_IFLOT будет являться окаймляющей функцией вокруг стандартной BAPI. Параметры этой функции должны быть заданы по определенной маске, так как её вызов происходит динамически транзакций MASS для каждой записи отмеченной в этой транзакции для обработки.
На Рис. 19: FNMASS-01.png представлены входные и выходные параметры функционального модуля Y_TSH_MASS_CHANGE_IFLOT, который надо создать.


Рис 19. FNMASS-01.png: входные и выходные параметры функционального модуля Y_TSH_MASS_CHANGE_IFLOT
| Внимание |
| Обратите внимание на то, что имена параметров и типы должны быть заданы в таком же виде, как показано на Рис. 20: FNMASS-01.png, кроме закладки «Таблицы», правила формирования имен которой, будут описаны отдельно. |
Сам текст функционального модуля, реализующего обновление технических мест, представлен ниже. Обратите внимание на параметры заполнения журнала транзакции MASS, особенно на формирование ключа объекта. В данном случае ключ формируется очень просто, так как это код технического места. Например, если бы это были изменения карточек ОС, то там ключ объекта должен был бы быть как соединение трех полей: <Код БЕ> + <Номер карточки ОС> + <Субномер карточки ОС>, т.е. ключ должен однозначно определять обрабатываемую запись.
Переменная журнала ls_msg-objkey должна содержать ключ обрабатываемого объекта. В дальнейшем, при вызове функций просмотра или изменения этот ключ будет передаваться в заданные вами функциональные модули, чтобы вы смогли перейти к выдранному пользователем объекту. Для просмотра объекта мы объявляли функцию Y_TSH_MASS_VIEW_IFLOT, Рис. 20: FNMASS-02.png

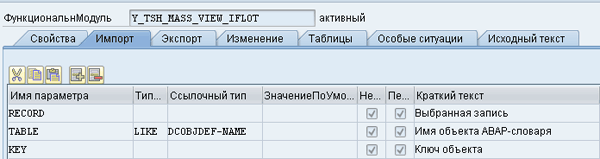
Рис 20. FNMASS-02.png
Сам текст модуля очень простой:


Аналогично выполняется объявление функционального модуля для изменений обрабатываемых объектов Y_TSH_MASS_EDIT_IFLOT, Рис. 21: FNMASS-03.png

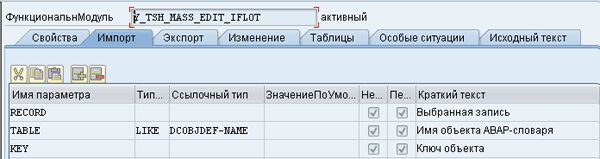
Рис 21. FNMASS-03.png
Текст функционального модуля практически такой же, как и при просмотре, отличается только код транзакции:
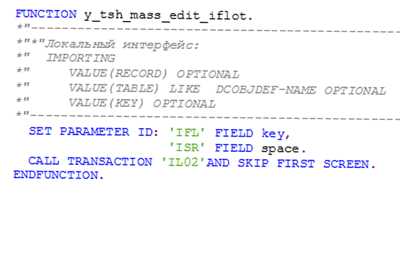

Итак, фактически за три часа рабочего времени была создана настройка и разработка для массового изменения технических мест, при этом, если нужно добавить какие-то дополнительные поля для обработки, то их просто нужно внести в ракурс ведения YTSH_IFLOTSTRUCT, конечно при условии, что эти переменные находятся только в таблице IFLOT. Функциональный модуль изменения технических мест, написан так, что корректно будет обрабатывать такие добавления.



















Комментарий от
Галина Нудьга
| 01 апреля 2015, 14:49
У системы много возможностей, но хотелось бы узнать и о недостатках.