Транзакция LSMW инструкция по применению. Часть 7
В этой книге приводятся практические решения задач с использованием транзакции
LSMW для загрузки данных на основе методов Batch Input, BAPI и
Direct Input. Примеры базируются на бизнес-сценарии миграции данных.
Загрузка остатков ОЗМ методом BAPI в транзакции LSMW
Продолжение книги.
Часть 1 Часть 2 Часть 3 Часть 4 Часть 5 Часть 6
В этой главе будет описано использование BAPI-метода на примере загрузки остатков (создание документов материала 561 видом движения). В основе подхода лежит использование типа сообщения MBGMCR, который вызывает BAPI_GOODSMVT_CREATE. BAPI-метод уже был подробно описан в главе 2, поэтому в настоящей главе не будут описываться шаги подробно, а детальное описание будет уделено новой информации. В решении бизнес-задачи мы находимся на этапе загрузки остатков по созданным ОЗМ (рис. 5.1). В примере будет показано, как создать множество документов материалов с несколькими позициями, используя один входной файл.
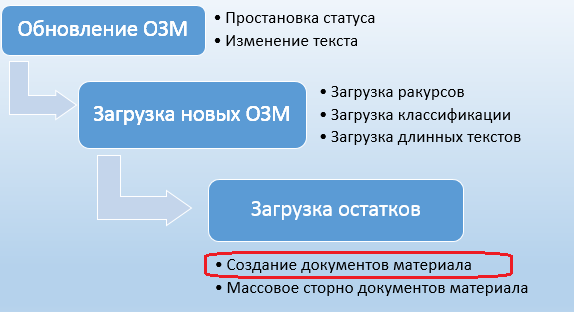
Рис. 5.1. Задача загрузки остатков в общей схеме задач миграции
Задача состоит в загрузке начальных остатков по разным субсчетам счета запасов (10-го счета в плане счетов Минфина РФ). В главе будет показан пример использования одного файла для двух входных структур (использование опции Identifying Field Content); будет показан пример использования маски в имени файла (Wildcard option); пример создания и применения параметра селекционного экрана, а также примеры дополнительного ABAP-кода посредством user-defined routines и работа с полями типа DDMY (дата) и AMT1 (сумма).
5. 1. Операционные условия
Требуется прогрузить остатки на склад с помощью 561-го вида движения на основные записи материалов; при этом нужно обеспечить загрузку нескольких позиций документов материала с помощью одного входного файла; также необходимо сделать возможным параллельную загрузку по разным субсчетам (чтобы для разных субсчетов был свой файл на сервере). Вводные данные для загрузки представлены в таблице 5.1. Для загрузки нескольких позиций в документе материала нам нужно использовать две структуры-источника. Однако для этих двух структур мы можем использовать один файл с данными. Для этого часть полей нам придется задублировать в структурах, но дублирования данных при этом не будет.
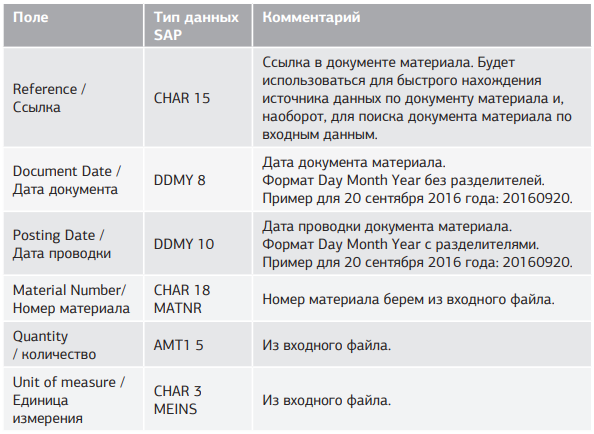
Табл. 5.1. Используемые переменные поля для загрузки остатков
Пройдемся вручную через MIGO по полям документ материала, обозначенным в таблице 5.1, и создадим документ материала. Созданный документа материала представлен на рис. 5.2.
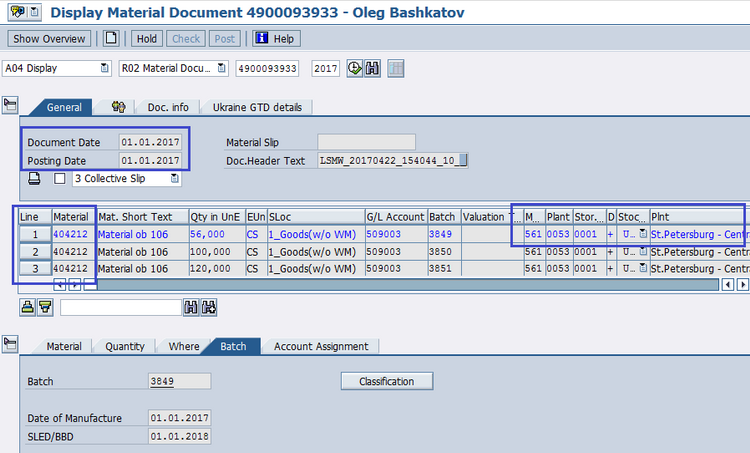
Рис. 5.2. Создание документа материала для начальной загрузки остатков
5.2. Пошаговое решение задачи
Шаг 1: создание/выбор проекта, подпроекта и объекта
Для создания нового проекта транзакции LSMW будем использовать данные из таблицы 5.2.

Табл. 5.2. Данные для создания объекта LSMW
После указания данных подтверждаем ввод и запускаем проект. Система откроет перед нами основное меню транзакции LSMW.
Шаг 2: параметры метода загрузки: выбор объекта и метода
Дважды щелкаем по пункту меню Maintain Object Attributes. В качестве объекта метода Business Object выбираем BUS2017 (Goods Movement), метод — CREATEFROMDATA (Post Goods Movement) (рис. 5.3).
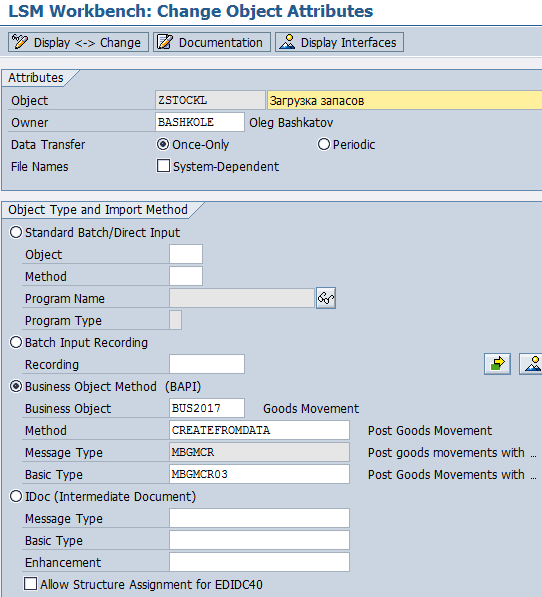
Рис. 5.3. Указываем объект и метод для использования BAPI-метода
Сохраняем и выходим к обзору списка шагов, чтобы перейти к следующему шагу.
Шаг 3: создание структуры источника [данных]
Переходим к пункту Maintain Source Structures. Создаем структуры ZDOCHEAD (Заголовок документа материала) и ZDOCITEM (Позиции документа материала). Система отобразит экран, как на рис. 5.4. Затем сохраняем и выходим, чтобы перейти к следующему шагу.
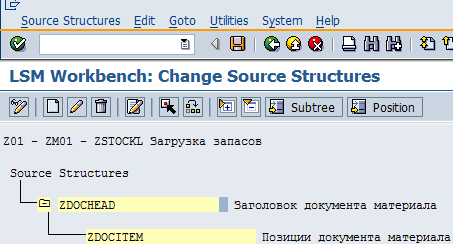
Рис. 5.4. Созданная структура загрузки данных
Шаг 4: ведение полей структуры источника [данных]
Щелкаем дважды по пункту Maintain Source Fields. Ставим курсор на структуру ZDOCHEAD (Заголовок документа материала) и нажимаем на кнопку Table Maintenance (рис. 5.5). Поля для структур ZDOCHEAD и ZDOCITEM приведены в таблице 5.3. При заполнении типов данных полей обратим внимание, что для даты имеется три формата DDMY, DMDY, DYMD, при этом каждый из форматов может быть как с разделителем, так и без него. Для суммы имеется четыре формата: AMT1, AMT2, AMT3, AMT4. Из описания видно, чем отличаются форматы (рис. 5.6).
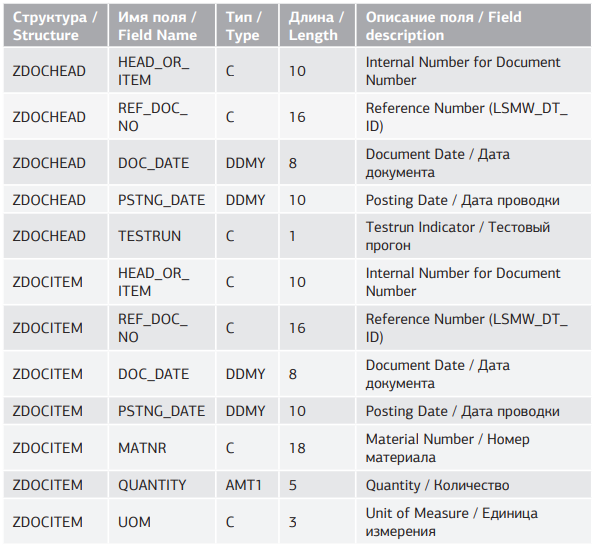
Табл. 5.3. Поля структуры источника ZDOCHEAD (заголовок документа материала)
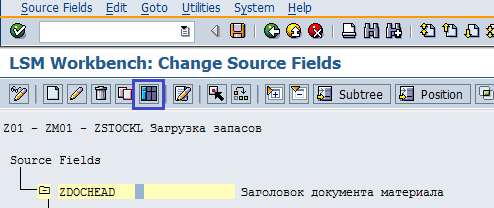
Рис. 5.5. Используем ввод через таблицу (Table Maintenance)
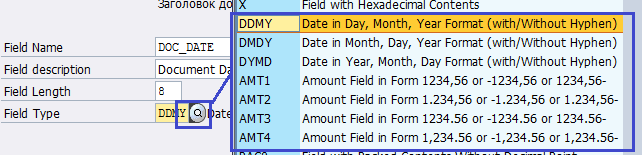
Рис. 5.6. Пояснение к форматам даты и суммы в транзакции LSMW
После заполнения данных касательно полей структур система отобразит экран, как показано на рис. 5.7.
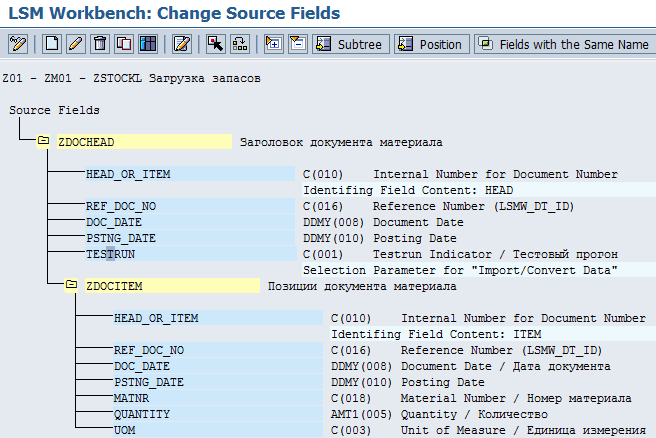
Рис. 5.7. Входные структуры с полями
На этом шаге нам нужно заполнить атрибут Identifying Filed Content в заголовочной и позиционной структурах. Это поле позволит нам использовать один файл для двух структур. Использование одного файла удобнее и надежнее, чем использование двух. Поле, которое позволит нам различить заголовок и позицию, будет HEAD_OR_ITEM. Дважды щелкаем по этому полю для структуры ZDOCHEAD, система отобразит экран, в котором мы укажем значение для поля Identifying Field Content — HEAD (рис. 5.8).
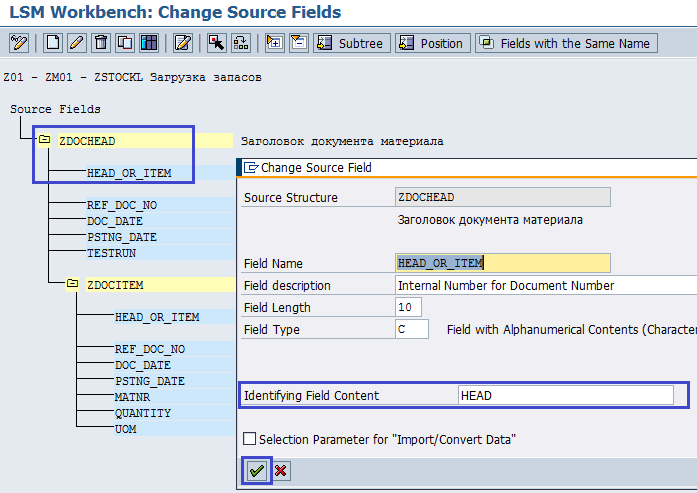
Рис. 5.8. Заполнение поля Identifying Field Content для структуры ZDOCHEAD значением HEAD
Затем проделаем похожие действия, но для структуры ZDOCITEM поля HEAD_OR_ITEM. Дважды щелкнем по этому полю и укажем значение для поля Identifying Field Content — ITEM (рис. 5.9).
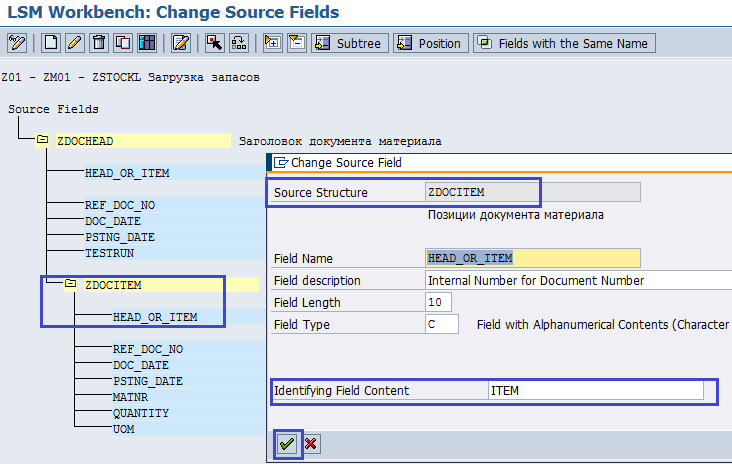
Рис. 5.9. Заполнение поля Identifying Field Content для структуры ZDOCITEM значением ITEM
Нам необходимо вывести поле TESTRUN на селекционный экран. Для этого дважды щелкаем по полю TESTRUN в структуре ZDOCHEAD и отмечаем галкой атрибут Selection Parameter for Import/Convert Data (рис. 5.10).
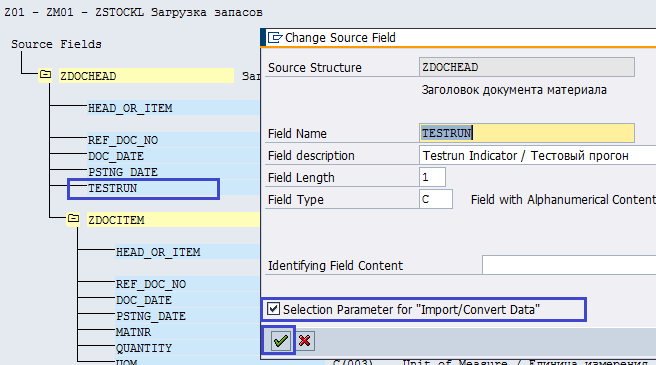
Рис. 5.10. Обозначаем поле в качестве селекционного параметра экрана
В основном экране шага сохраняем данные и выходим к обзору шагов, чтобы перейти к следующему шагу.
Шаг 5: соответствие структур источника данных и записи
Дважды щелкаем по шагу Maintain Structure Relations. Создаем соответствие структур, как показано на экране (рис. 5.11). Сохраняем, выходим, переходим к следующему шагу.

Рис. 5.11. Присвоение структуры входного файла и внутренних структур и структур типа сообщения
Шаг 6: мэппинг (соответствие) полей источника [данных] и полей структур BAPI и User-defined routines
Дважды щелкаем по шагу Maintain Field Mapping and Conversion Rules. На данном шаге производим мэппинг полей входного файла и структуры BAPI. Предварительно с помощью кнопки Layout откроем дополнительные области, где можно указать ABAP-код (рис. 5.12).
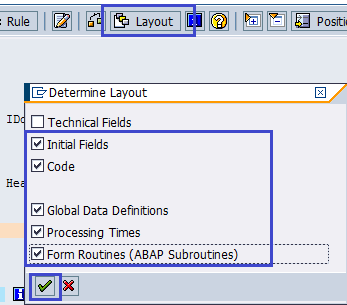
Рис. 5.12. Открываем поля для дополнительного ABAP-кода
Пройдемся по блокам и полям и произведем мэппинг; данные для мэппинга приведены в таблицах 5.4.а–5.4.б.
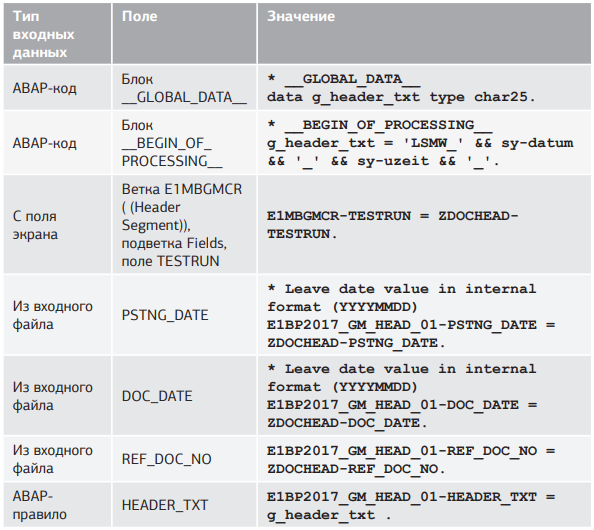
Табл. 5.4.а. Мэппинг полей структур BAPI и входного файла
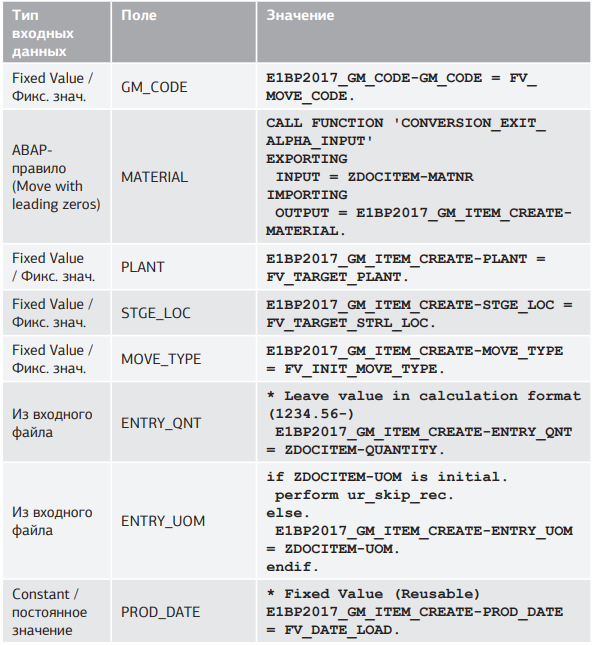
Табл. 5.4.б. Мэппинг полей структур BAPI и входного файла
Чтобы присвоить фиксированное значение (Fixed Value) полю, нужно поставить курсор на поле и нажать на кнопку Fixed Value, в открывшемся поле ввести переменную (если она не существует, то система предложит создать ее) (рис. 5.13).
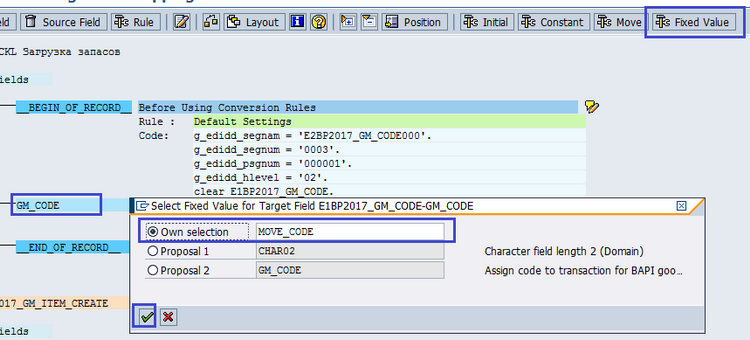
Рис. 5.13. Указание Fixed Value (фиксированного значения) для поля
Также заметим, что мы можем вести подпрограммы для всего проекта (так называемые user defined routines) и ABAP-routines для конкретного загрузчика, которые доступны в самом конце загрузчика (рис. 5.14).
Рис. 5.14. Место в загрузчике для ABAP-подпрограмм, специфичных для отдельного объекта LSMW (загрузчика)
В нашем случае мы будем создавать подпрограмму, общую для всего проекта, то есть в пункте меню Maintain Fixed Values, Translations, User-Defined Routines (рис. 5.15).
Рис. 5.15. Пункт меню Maintain Fixed Values, Translations, User-Defined Routines
Мы сослались на несколько фиксированных значений (Fixed Value) и одну подпрограмму (User defined routines). Чтобы задать значение для Fixed Value, нужно поставить курсор на нужное Fixed Value и нажать пиктограмму Change / Изменить (рис. 5.16), затем ввести нужное описание и значение.
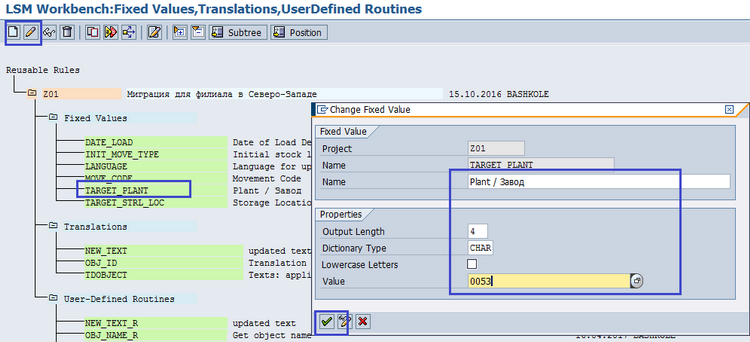
Рис. 5.16. Задаем описание и значение для FixedValue TARGET_PLANT
Данные по остальным фиксированным значениям (Fixed Value) приведены в таблице 5.5.
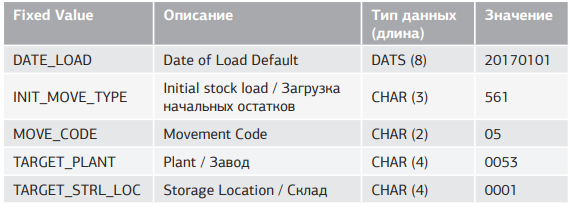
Табл. 5.5. Данные по фиксированным значениям (Fixed Value)
Обратим внимание, что на экране фиксированное значение может идентифицироваться, например, как MOVE_CODE, а вот обращение к ней в программе происходит по имени переменной fv_move_code (то есть добавляется префикс fv).
Теперь переходим к определенной пользователем подпрограмме SKIP_RECORD. Назначение этой подпрограммы — правильно указать системе, что текущую запись нужно пропустить. В нашем случае запись — это позиция документа материала, а транзакция — весь документ материала. Мы пропускаем весь документ материала в случае, если единица измерения на входе отсутствует хотя бы в одной позиции. Ставим курсор на нужную нам User-Defined Routines и переходим к изменению с помощью пиктограммы Change / Изменить (кнопка с карандашом) (рис. 5.17).
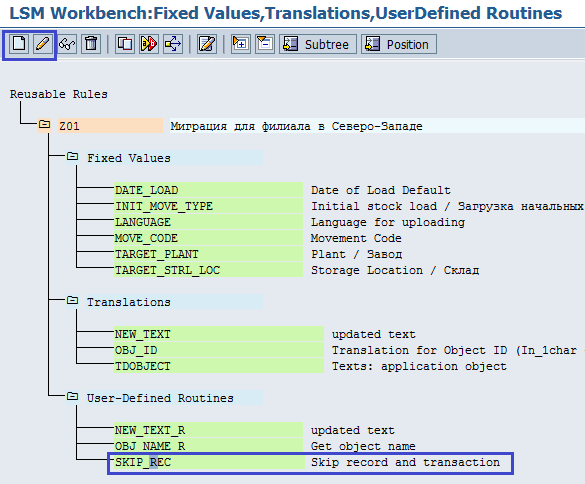
Рис. 5.17. Переходим к редактированию подпрограммы skip_rec
Обратим внимание, что техническое имя подпрограммы — ur_SKIP_REC. Нужный код для подпрограммы приведен в таблице 6. Обратим внимание и на то, что ни одну из переменных мы не определяем. Переменные g_skip_record, g_transfer_record, g_skip_transaction и g_transfer_transaction специально служат для целей пропуска записей и определены глобально; равно как и константы yes и no (таблица 5.6).

Табл. 5.6. Код для user-defined routines SKIP_REC
Затем сохраняем и переходим к основному меню транзакции LSMW (рис. 5.18).
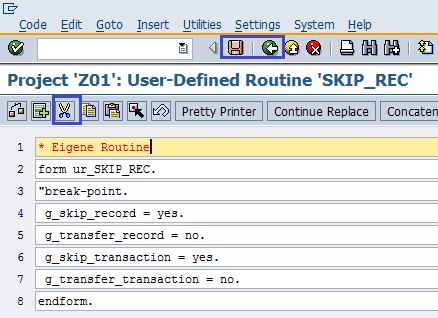
Рис. 5.18. Сохранение user-defined routines
После создания нужных fixed values и user-defined routines полезным будет вернуться в шаг Maintain Field Mapping and Conversion Rules и нажать кнопку 
 Check Syntax (рис. 5.19).
Check Syntax (рис. 5.19).
Рис. 5.19. Проверка синтаксиса программы
В случае наличия ошибок система откроет ABAP-редактор, в котором необходимо снова запустить проверку программы, и тогда система явно укажет, в чем ошибка. В нашем случае ошибок нет, но сообщение могло бы выглядеть, как показано на рис. 5.20.
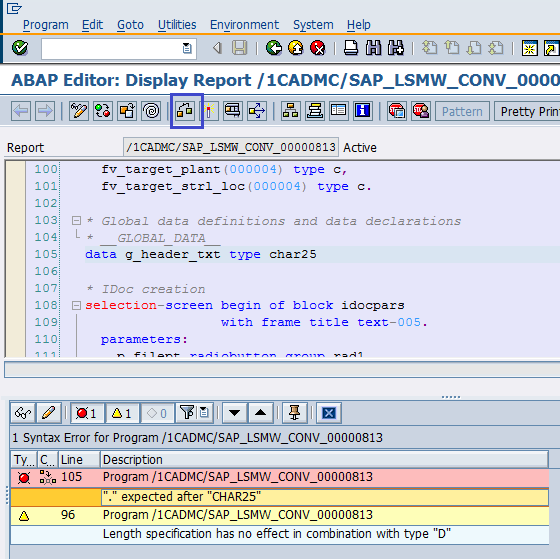
Рис. 5.20. Пример сообщения об ошибке в ABAP-редакторе
Теперь можно переходить к следующему шагу для указания входного файла и его параметров.
Шаг 7: указание пути к файлу
Прежде чем указывать путь к файлу, необходимо создать файлы по нужному нам формату. Для создания входного файла будем использовать Excel. Первую строку в Excel заполним техническими именами полей входной структуры. А строки, начиная со 2-й, заполним уже конкретными значениями. В нашем случае у нас может быть несколько входных файлов, так как данные по каждому субсчету мы будем хранить в отдельном файле. Для разделения файлов мы будем использовать Wildcard. При этом для заполнения заголовка и позиций документа материала мы будем использовать один и тот же файл. На рис. 5.21 показан файл для загрузки субсчета 10–01, а на рис. 5.22 показан файл для загрузки субсчета 10–08. Как видно, формат файлов одинаков, но данные в них разные и контроль за данными также будет осуществляться по-разному.
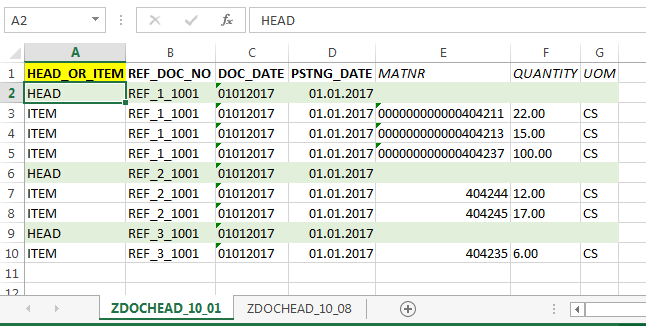
Рис. 5.21. Пример заполнения входного шаблона по субсчету 10–01 (сырье и материалы)
С помощью атрибута HEAD_OR_ITEM мы сделали разделение строк на данные заголовка и данные позиции. Таким образом, мы можем использовать один и тот же файл для наполнения данных заголовка и данных позиций и при этом загружать более чем одну позицию в документе материала. А за счет того что часть столбцов мы продублировали в позиционной структуре, мы можем себе позволить вести файл в табличном формате. Дважды щелкнем по Specify Files (рис. 5.22).
Если хотите прочитать статью полностью и оставить свои комментарии присоединяйтесь к sapland
ЗарегистрироватьсяУ вас уже есть учетная запись?
Войти